




什么是正则表达式
正则表达式是对字符串操作的一种逻辑公式,就是用事先定义好的一些特定字符、及这些特定字符的组合,组成一个“规则字符串”,这个“规则字符串”用来表达对字符串的一种过滤逻辑
正则表达式规则
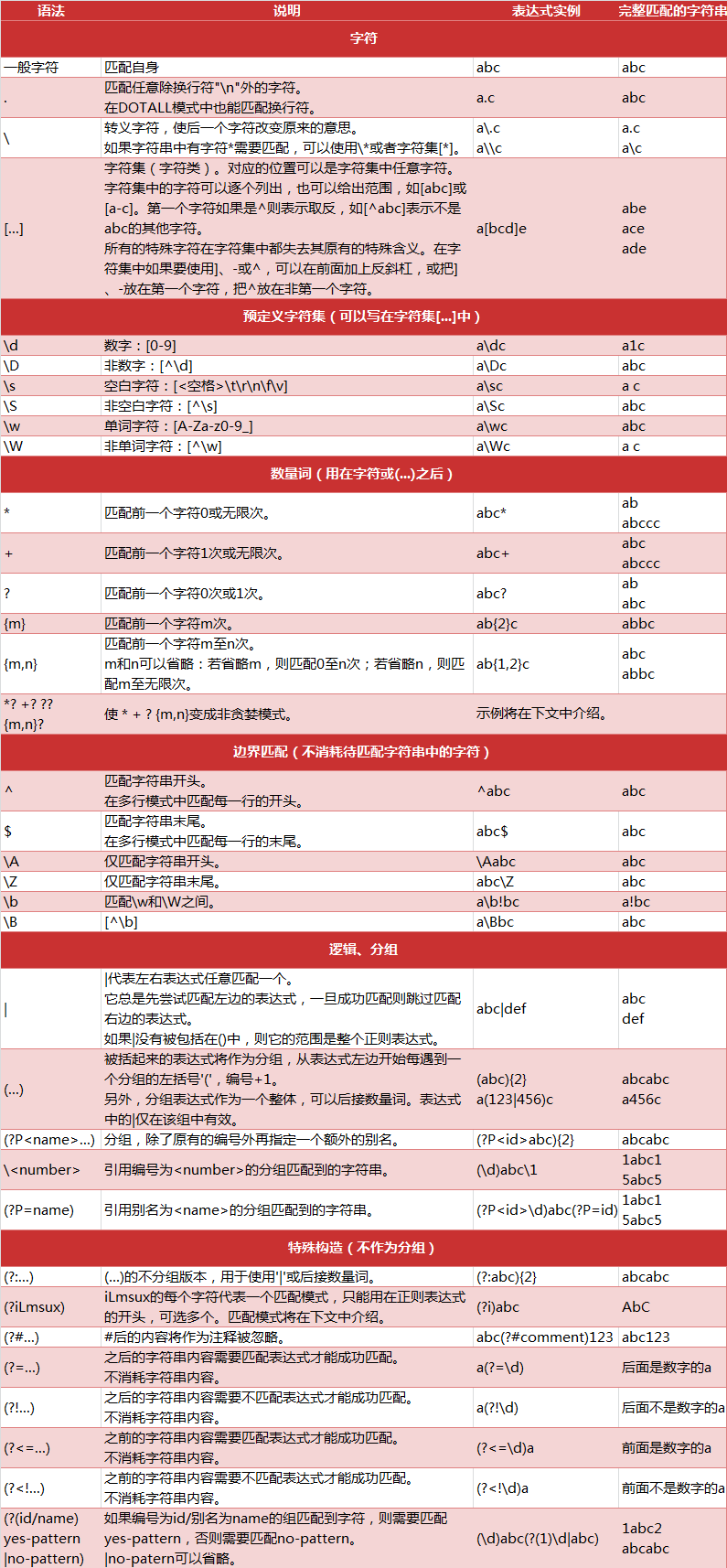
正则表达式注意问题
数量词的贪婪模式与非贪婪模式
正则表达式通常用于在文本中查找匹配的字符串。Python里数量词默认是贪婪的,总是尝试匹配尽可能多的字符;非贪婪的则相反,总是尝试匹配尽可能少的字符。
例如:正则表达式”ab”如果用于查找”abbbc”,将找到”abbb”。
而如果使用非贪婪的数量词”ab?”,将找到”a”。
*表示匹配前一个字符0个或多个,加上?后匹配前一个字符0个或1个,使匹配规则变为非贪婪。
转义问题
由于字符串中出现特殊字符要采取转义,采用'\'可以进行转义。如果字符串中出现'\',需要采用'\'才可以转义为'\', Python里的原生字符串很好地解决了这个问题,在字符串前加上r,表示原生字符串,不用考虑转义问题。 看下面的例子:
import re
s = 'AB\\-001'
print(s)
s = r'AB\-001'
print(s)
使用原生字符串不用写转义的'\'了。
正则表达式的应用举例
1 可以re模块中的match函数实现基本的匹配
import re
result = re.match(r'^\d{3}\-\d{3,8}$','010-12345')
print(result)
result2 = re.match(r'^\d{3}\-\d{3,8}$','010 12345')
print(result2)
2 可以实现split切割字符串
#切串
s1 = 'a b c'
print(s1.split(' ') )
s2 = re.split(r'\s+', s1)
print(s2)
s3 = re.split(r'[\s\:\,]+','a,b c::d e, f')
print(s3)
pattern = re.compile(r'\d+')
splitrs = re.split(pattern, 'one1two2three3four45six797five')
if sr:
print(splitrs)
3 对匹配规则进行分组
m = re.match(r'^(\d{3})-(\d{3,8})$','010-12345')
print(m)
print(m.group(0))
print(m.group(1))
print(m.group(2))
print(m.groups())
4 贪婪匹配和非贪婪匹配
r1 = re.match(r'^(\d+)(0*)$','102300').groups()
print(r1)
r2 = re.match(r'^(\d+?)(0*)$','102300').groups()
print(r2)
5 编译生成pattern再匹配
re_telephone = re.compile(r'^(\d{3})-(\d{3,8})$')
r3 = re_telephone.match('010-12345').groups()
print(r3)
r4 = re_telephone.match('043-12345').groups()
print(r4)
match 的另一种写法是这样的
pattern = re.compile(r'hello')
result1 = re.match(pattern, 'hello')
result2 = re.match(pattern, 'helloo, aaa')
result3 = re.match(pattern, 'helo AAB')
result4 = re.match(pattern, 'helloww')
if result1:
print(result1 )
else:
print('failed!!!')
if result2:
print(result2.group() )
else:
print('failed!!!')
if result3:
print(result3.group() )
else:
print('failed!!!')
if result4:
print(result4.group() )
else:
print('failed!!!')
re.compile返回值包含如下属性和函数:
属性:
1.string: 匹配时使用的文本。
2.re: 匹配时使用的Pattern对象。
3.pos: 文本中正则表达式开始搜索的索引。值与Pattern.match()和Pattern.seach()方法的同名参数相同。
4.endpos: 文本中正则表达式结束搜索的索引。值与Pattern.match()和Pattern.seach()方法的同名参数相同。
5.lastindex: 最后一个被捕获的分组在文本中的索引。如果没有被捕获的分组,将为None。
6.lastgroup: 最后一个被捕获的分组的别名。如果这个分组没有别名或者没有被捕获的分组,将为None。
函数:
1.group([group1, …]):
获得一个或多个分组截获的字符串;指定多个参数时将以元组形式返回。group1可以使用编号也可以使用别名;编号0代表整个匹配的子串;
不填写参数时,返回group(0);没有截获字符串的组返回None;截获了多次的组返回最后一次截获的子串。
2.groups([default]):
以元组形式返回全部分组截获的字符串。相当于调用group(1,2,…last)。default表示没有截获字符串的组以这个值替代,默认为None。
3.groupdict([default]):
返回以有别名的组的别名为键、以该组截获的子串为值的字典,没有别名的组不包含在内。default含义同上。
4.start([group]):
返回指定的组截获的子串在string中的起始索引(子串第一个字符的索引)。group默认值为0。
5.end([group]):
返回指定的组截获的子串在string中的结束索引(子串最后一个字符的索引+1)。group默认值为0。
6.span([group]):
返回(start(group), end(group))。
7.expand(template):
将匹配到的分组代入template中然后返回。template中可以使用\id或\g、\g引用分组,但不能使用编号0。\id与\g是等价的;
但\10将被认为是第10个分组,如果你想表达\1之后是字符’0’,只能使用\g0。
下面的例子将上述属性和函数打印出来,读者可以打印看看结果
#匹配:单词+空格+单词+任意字符
m = re.match(r'(\w+) (\w+)(?P<sign>.*)','hello world!')
print('m.string is %s' %(m.string) )
print('m.re: %s' %(m.re) )
print('m.pos: %d' %(m.pos))
print('m.endpos: %d' %(m.endpos))
print('m.lastindex: %d' %(m.lastindex))
print('m.lastgroup: %s' %(m.lastgroup))
print('m.groups: ' , m.groups())
print('m.group: ' , m.group())
print('m.group(1,2): ' , m.group(1,2))
print('m.groupdict():', m.groupdict())
print('m.start(2):',m.start(2))
print('m.end(2):',m.end(2))
print('m.span(2):',m.span(2))
print("m.expand(r'\g \g\g'):", m.expand(r'\2 \1\3') )
除此之外还有其他的几个函数
6 re.search(pattern, string[, flags])
search方法与match方法极其类似,区别在于match()函数只检测re是不是在string的开始位置匹配,search()会扫描整个string查找匹配
import re
pattern = re.compile(r'world')
sr = re.search(pattern, 'hello world!')
if sr:
print(sr.group())
7 re.findall(pattern, string[, flags])
搜索string,以列表形式返回全部能匹配的子串。
pattern = re.compile(r'\d+')
find = re.findall(pattern, 'one1two2three3four45six797five')
if find:
print(find)
8 re.finditer(pattern, string[, flags])
搜索string,返回一个顺序访问每一个匹配结果(Match对象)的迭代器。
pattern = re.compile(r'\d+')
finditer = re.finditer(pattern, 'one1two2three3four45six797five')
if(finditer):
print(finditer)
for m in finditer:
print(m.group())
9 re.sub(pattern, repl, string[, count])
使用repl替换string中每一个匹配的子串后返回替换后的字符串,首先根据pattern在string中匹配,找到子串返回列表,然后根据repl规则,
替换列表中的字符串。
pattern = re.compile(r'(\w+) (\w+)')
s = 'i say, hello world'
print(re.sub(pattern,r'\2 \1', s))
def func(m):
return m.group(1).title() + ' '+ m.group(2).title()
sub = re.sub(pattern, func, s)
print(sub)
10 re.subn(pattern, repl, string[, count])
返回 一个tuple,tuple两个元素,第一个为re.sub(pattern, repl, string[, count])的结果,第二个为匹配的子串个数。
pattern = re.compile(r'(\w+) (\w+)')
s = 'i say, hello world'
print(re.subn(pattern,r'\2 \1', s))
def func(m):
return m.group(1).title() + ' '+ m.group(2).title()
sub = re.subn(pattern, func, s)
print(sub)
到目前为止正则表达式基本知识介绍完毕,谢谢关注我的公众号
