




这一篇巩固前几篇文章的学到的技术,利用urllib库爬取美女图片,其中采用了多线程,文件读写,
目录匹配,正则表达式解析,字符串拼接等知识,这些都是前文提到的,综合运用一下,写个爬虫
示例爬取美女图片。
先定义几个匹配规则和User_Agent
USER_AGENT = 'Mozilla/5.0 (Windows NT 6.1; WOW64) AppleWebKit/537.36 (KHTML, like Gecko) Chrome/49.0.2623.221 Safari/537.36 SE 2.X MetaSr 1.0'
PATTERN1 = r'<div id="content">.*?<h2>(.*?)</h2>'
PATTERN2 = r'<p><img src="(.*?)"'
PATTERN2 = r'<p><img class=".*?src="(.*?)"'
PATTERN3 = r'''<li class='next-page'><a target="_blank" href='(.*?)'>下一页'''
PATTERN4 = r'^(.*)/'
PATTERN5 = r'^.*/(.*?)$'
读者可以根据不同网站的代码去修改这些规则,达到匹配一些网站的目的。
1定义抓图类
class GetMMPic(object):
def __init__(self,path,httpstr):
# 去除首位空格
path = path.strip()
# 去除尾部 \ 符号
path = path.rstrip('\\')
self.path = path
self.url = httpstr
self.user_agent = USER_AGENT
初始化构造函数中设置了路径和网络地址,以及请求的user_agent。
2封装信息请求和读取函数
def requestData(self,url, user_agent):
try:
req = request.Request(url)
req.add_header('User-Agent', user_agent)
response = request.urlopen(req,timeout = 8)
#bytes变为字符串
content = response.read().decode('utf-8')
return content
except error.URLError as e:
if hasattr(e,'code'):
print (e.code)
if hasattr(e,'reason'):
print (e.reason)
except error.HTTPError as e:
if hasattr(e,'code'):
print(e.code)
if hasattr(e,'reason'):
print(e.reason)
print('HTTPError!!!')
这个函数功能主要是请求url网络地址,加上user_agent后,获取数据,并且采用utf-8 编码方式解析。
3封装创建目录函数
def makedir(self,dirname):
joinpath = os.path.join(self.path,dirname)
print(joinpath)
isExists = os.path.exists(joinpath)
if isExists:
print('目录已经存在\n')
return None
else:
os.makedirs(joinpath)
print('创建成功\n')
return joinpath
该函数主要是完成在GMMPic类配置的路径下(默认是./),生成子目录,子目录的名字由 参数决定。简单地说就是要在当前目录下生成文件名对应的文件夹,保存不同的图片。
4 获取当前页面信息保存图片
def getPageData(self,httpstr):
content = self.requestData(self.url, self.user_agent)
namepattern = re.compile(PATTERN1,re.S)
nameresult = re.search(namepattern, content)
namestr = nameresult.group(1)
dirpath = self.makedir(namestr)
if not dirpath:
print('目录已存在')
return
picpattern = re.compile(PATTERN2,re.S)
lastpattern = re.compile(PATTERN5, re.S)
while(1):
print('正在爬取%s........'%(namestr))
picitems = re.findall(picpattern,content)
for item in picitems:
picrs = re.search(lastpattern, item)
picname = picrs.group(1)
filedir = os.path.join(dirpath,picname)
url = quote(item, safe = string.printable)
try:
req = request.Request(url)
req.add_header('User-Agent',USER_AGENT)
response = request.urlopen(req)
picdata =response.read()
with open(filedir,'wb') as file:
file.write(picdata)
except error.URLError as e:
if hasattr(e,'code'):
print (e.code)
if hasattr(e,'reason'):
print (e.reason)
except error.HTTPError as e:
if hasattr(e,'code'):
print (e.code)
if hasattr(e,'reason'):
print (e.reason)
print('\n%s爬取成功.......'%(namestr))
break
getPageData()函数根据PATTERN2匹配页面符合条件的图片资源,根据PATTERN5取出图片名字(不含类型), 通过for循环一个一个保存。
运行程序,提示输入网址,
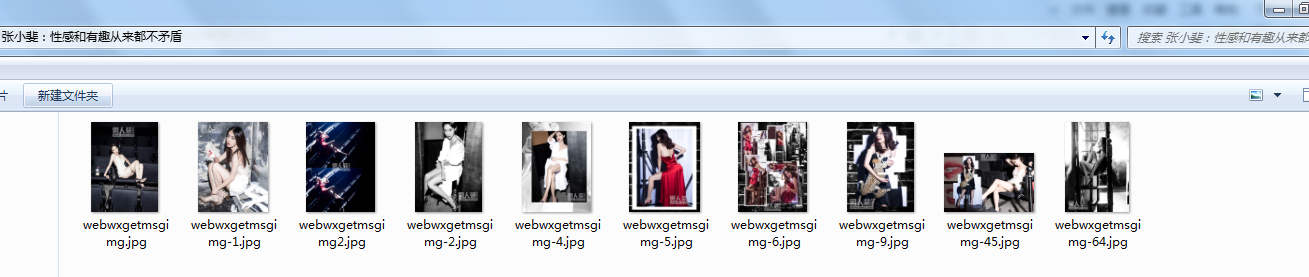
 这里输入男人装某篇文章的地址,效果如下:
这里输入男人装某篇文章的地址,效果如下:
5 采用多线程提高并发能力
编写线程回调函数 workthread, 每个线程去爬不同的文章
def workthread(item, user_agent,path):
strurl = 'http://yxpjw.club'+item[0]
picname = item[1]
print('正在爬取%s...........................\n' %(picname))
content = requestData(strurl,user_agent)
strurl2 = re.search(r'^(.*)/',strurl).group(0)
print('https headers...............%s'%(strurl2))
#destname = os.path.join(path,picname+'.txt')
#with open(destname, 'w',encoding='gbk') as file:
#file.write(content)
destdir = os.path.join(path,picname)
os.makedirs(destdir)
page = 1
while(1):
content = getpagedata(content,destdir,page,strurl2)
if not content:
break
page = page + 1
print('%s数据爬取成功!!!\n'%(picname))
开辟多个线程,去爬首页各个分栏,实现自动化抓图
def getDetailList(self,content):
s2 = r'<h2><a target="_blank" href="(.*?)" title="(.*?)"'
pattern =re.compile(s2 , re.S
)
result = re.findall(pattern, content)
with open('file.txt','w',encoding='gbk') as f:
f.write(content)
if not result:
print('匹配规则不适配..............')
threadsList=[]
for item in result:
t = threading.Thread(target = workthread, args=(item, self.user_agent, self.path))
threadsList.append(t)
t.start()
for threadid in threadsList:
threadid.join()
用修改后的多线程程序爬取宅福利首页各模块图片
效果如下:


源码下载地址:
https://github.com/secondtonone1/python-
谢谢关注我的公众号:
