




简介
到目前为止,前面一系列的文章已经将多线程编程技术介绍完了,很多人问我如何排查多线程程序的问题,本节是最后一节,给大家提供一些在多线程编程过程中排查问题的思路。因为本节代码演示和实际操作内容较多,该文档仅做基本的说明,详细操作可看视频, 视频链接:
https://space.bilibili.com/271469206/channel/collectiondetail?sid=1623290
常见问题
在介绍如何排查前我们先将问题做几个归类:
- 内存问题,包括内存泄露(未回收内存),空指针,悬垂指针(野指针),double free问题等。
- 资源竞争,多个线程竞争同一块临界区的资源,未保证互斥
- 死锁(互相引用阻塞卡死)和活锁(乐观锁尝试)
- 引用已释放的变量,生命周期管理失效导致
- 浅拷贝造成内存异常
- 线程管控失败,修改或者回收一个已经绑定正在运行线程的变量,或者线程本该回收却被卡死,皆因线程管控失败导致
- 智能指针和裸指针混用导致二次析构,也属于double free。
接下来根据上面列出的问题,我们根据实际案例排查出现问题的原因以及规避的方法。
接下来的案例均取自我的源码,源码链接如下:
https://gitee.com/secondtonone1/boostasio-learn/tree/master/concurrent/day24-TroubleShoot
空指针
空指针的问题比较好排查,我们在封装无锁队列的时候照抄《C++并发编程实战》一书引发了崩溃,详见源码链接中crushque.h以及lockfreequetest.cpp。
测试用例如下:
void TestCrushQue() {
crush_que<int> que;
std::thread t1([&]() {
for (int i = 0; i < TESTCOUNT * 10000; i++) {
que.push(i);
std::cout << "push data is " << i << std::endl;
std::this_thread::sleep_for(std::chrono::milliseconds(10));
}
});
std::thread t2([&]() {
for (int i = 0; i < TESTCOUNT * 10000;) {
auto p = que.pop();
if (p == nullptr) {
std::this_thread::sleep_for(std::chrono::milliseconds(10));
continue;
}
i++;
std::cout << "pop data is " << *p << std::endl;
}
});
t1.join();
t2.join();
}
最后显示的崩溃点在

很明显这是引发崩溃的底层代码,并不是上层代码,通过调用堆栈找到和崩溃最相近的逻辑
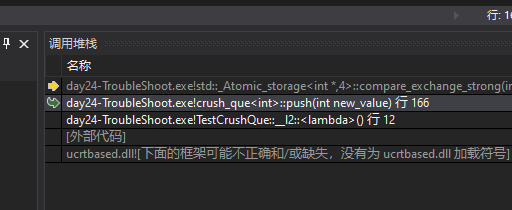
我们点击第二行的栈调用跳转到队列的push操作。
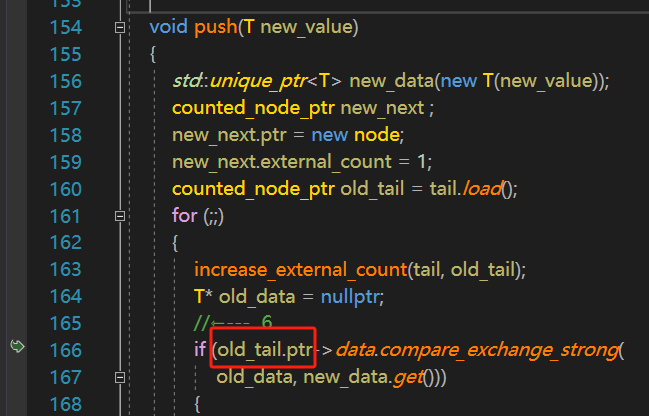
在代码166行处是崩溃的上层调用,我们通过分析old_tail.ptr此时为空指针,该问题的根因在于构造无锁队列时未进行头节点和尾部节点的初始化所致。
无论linux还是windows,排查崩溃问题最首要的解决方式为观察栈调用,gdb或者windows的栈信息直观的反应了崩溃的触发顺序。
内存泄漏
一般来说内存泄漏检测有专门的工具库,linux环境下可使用valgrind,windows的visual studio环境下Visual Leak Detector, 这些工具只能被动的检测内存泄漏,很多情况我们需要针对已经开发的类或者逻辑编写测试用例,检测内存泄漏。
比如我们对于无锁队列中提供了一个内存泄漏的版本,详见memoryleakque.h以及测试用例lockfreequetest.cpp,以下为测试代码
void TestLeakQue() {
memoryleak_que<int> que;
std::thread t1([&]() {
for (int i = 0; i < TESTCOUNT; i++) {
que.push(i);
std::cout << "push data is " << i << std::endl;
std::this_thread::sleep_for(std::chrono::milliseconds(10));
}
});
std::thread t2([&]() {
for (int i = 0; i < TESTCOUNT;) {
auto p = que.pop();
if (p == nullptr) {
std::this_thread::sleep_for(std::chrono::milliseconds(10));
continue;
}
i++;
std::cout << "pop data is " << *p << std::endl;
}
});
t1.join();
t2.join();
assert(que.destruct_count == TESTCOUNT);
}
针对这个队列, 我们统计释放节点的个数和开辟节点的个数是否相等,通过assert(que.destruct_count == TESTCOUNT);断言检测,实际测试过程中发现存在内存泄漏。
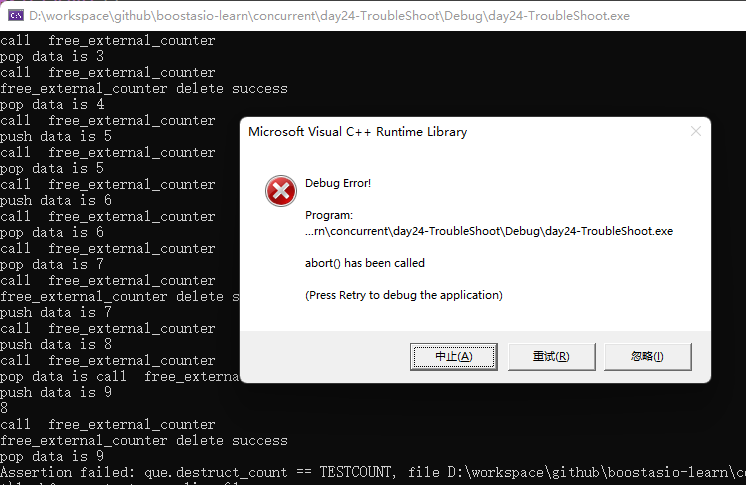
针对无锁队列的内存泄漏无外乎就是push和pop操作造成的,我们把测试用例改为单线程,先将多线程这个可变因素去掉
void TestLeakQueSingleThread() {
memoryleak_que<int> que;
std::thread t1([&]() {
for (int i = 0; i < TESTCOUNT; i++) {
que.push(i);
std::cout << "push data is " << i << std::endl;
std::this_thread::sleep_for(std::chrono::milliseconds(10));
auto p = que.pop();
if (p == nullptr) {
std::this_thread::sleep_for(std::chrono::milliseconds(10));
continue;
}
std::cout << "pop data is " << *p << std::endl;
}
});
t1.join();
assert(que.destruct_count == TESTCOUNT);
}
上面的代码测试未发现内存泄漏,但这还不能将问题归因于多线程,我们构造一种情况触发空队列的pop
void TestLeakQueMultiPop() {
memoryleak_que<int> que;
std::thread t1([&]() {
for (int i = 0; i < TESTCOUNT; i++) {
que.push(i);
std::cout << "push data is " << i << std::endl;
std::this_thread::sleep_for(std::chrono::milliseconds(10));
auto p = que.pop();
if (p == nullptr) {
std::this_thread::sleep_for(std::chrono::milliseconds(10));
continue;
}
std::cout << "pop data is " << *p << std::endl;
auto p2 = que.pop();
if (p2 == nullptr) {
std::this_thread::sleep_for(std::chrono::milliseconds(10));
continue;
}
std::cout << "pop data is " << *p2 << std::endl;
}
});
t1.join();
assert(que.destruct_count == TESTCOUNT);
}
上面的代码再一次触发断言,说明存在内存泄漏,那我们可以将问题归因于pop操作,而且是队列为空的pop操作。
接下来配合断点调试,windows断点调试较为方便,或者linux环境gdb调试麻烦,可以在关键点打印信息排查问题。
我们使用visual studio断点排查这个问题,先让队列push一个数据,再pop两次,第二次pop肯定无效因为是空队列,但也是引发泄漏的关键原因。
接下来再push一个数据,再pop节点,我们需观察这次pop是否会触发节点回收的逻辑。
回收节点的逻辑只有两处,在release_ref和free_external_counter内部判断internal_count和external_counters为0时才会调用delete回收内存,所以我们只需要在release_ref和free_external_counter中打断点,观察这两个引用计数是否为0,如果不为0说明引用计数的计算出了问题。
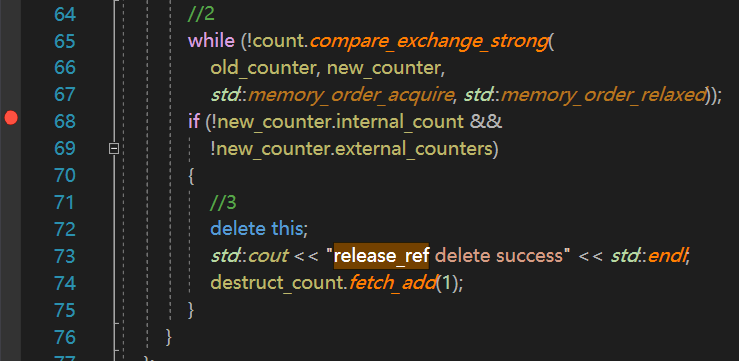
为了便于观察数据,我们采取单步调试的方式,经过断点调试,发现第二次循环pop时,free_external_count内部old_node_ptr.external_count为3,而第一次循环pop时old_node_ptr.external_count为2. 那么第二次计算internal_count就不会为0,导致节点不会回收。
问题的根因也找到了在pop判断队列为空的时候直接返回了,之前进行了increase_external_count将外部引用计数增加了,在判断队列为空未进行修改就返回了,我们知道外部引用计数只是一个副本,可能同时有多个线程修改外部引用计数,所以只需要让内部引用计数释放一次即可
if (ptr == tail.load().ptr)
{
ptr->release_ref();
return std::unique_ptr<T>();
}
再次测试未发现内存泄漏。
自己设计测试用例时要注意覆盖多种情况,比如无锁队列,我后来又测试了单线程,多线程一进一出,多线程一进多出,多线程一出多进,多线程多出多进等,以及加大线程数测试。详细案例可以看看源码, lockfreequetest.cpp。
double free
对于悬垂指针也叫做野指针,指的是释放内存后,再次使用这个指针访问数据造成崩溃。double free也属于指针管理失效导致,我们看看网络编程中对官方案例存在隐患的剖析。案例在网络编程network文件夹,day05-AsyncServer中,我们实现了一个异步的echo应答server。 正常情况下应答server没有任何问题,但是对于全双工情况(实际情况都是收发解耦合),比如我们在收到消息后监听读事件,并发送,而不是在发送消息后监听读事件。我们将handle_read处理改为如下
void Session::handle_read(const boost::system::error_code& error, size_t bytes_transfered) {
if (!error) {
cout << "server receive data is " << _data << endl;
std::string send_data(_data);
//在发送
_socket.async_read_some(boost::asio::buffer(_data, max_length), std::bind(&Session::handle_read,
this, placeholders::_1, placeholders::_2));
boost::asio::async_write(_socket, boost::asio::buffer(send_data, bytes_transfered),
std::bind(&Session::handle_write, this, placeholders::_1));
}
else {
delete this;
}
}
我们启动day04-SyncClient和day05-AsyncServer分别测试,在Server handle_read里async_read_some处打断点,然后启动客户端,客户端发送数据后服务器触发async_read_some断点,此时关闭客户端,然后服务器继续执行后面的逻辑会引发崩溃。
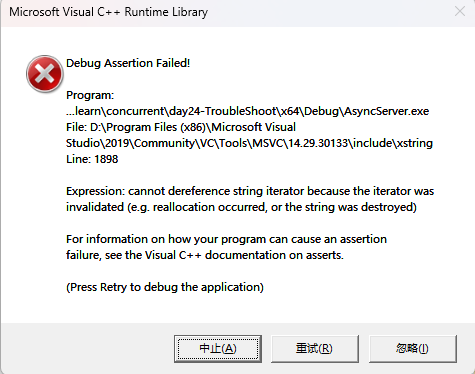
遇到崩溃第一反应是看看崩溃的栈信息,崩溃在最底层代码

栈信息也看不懂
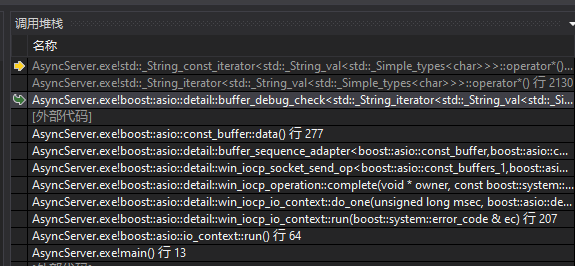
看栈调用应该是崩溃在asio底层iocp模型写回调里了。
那我们可以用注释的方式排查问题。我们把handle_write回调里面的逻辑注释掉
void Session::handle_write(const boost::system::error_code& error) {
// if (!error) {
// memset(_data, 0, max_length);
// _socket.async_read_some(boost::asio::buffer(_data, max_length), std::bind(&Session::handle_read,
// this, placeholders::_1, placeholders::_2));
// }
// else {
// delete this;
// }
}
再次启动客户端和服务器,在服务器收到读回调后断点并关闭客户端,服务器放开断点继续执行,未发现崩溃。
观察注释掉的逻辑,最有嫌疑的是delete this, 我们仅仅将delete this注释掉后就不会崩溃了,那我们找到问题根因了
第一次回调触发handle_read没问题,此时在回调里关闭客户端,因为第一次回调再次调用async_read_some将读事件注册给asio底层的事件循环,调用async_write将写事件注册给asio底层循环,当客户端关闭后会第二次触发读回调,这次读回调会执行delete操作,delete this之后,Session所有的数据都被回收,而写回调也会触发,因为那么就行了二次delete操作,这就是double free问题。
解决这个问题我们提出了利用智能指针构造一个伪闭包的方式延长Session周期,保证回调之前不会delete Session。具体可以看看这篇文章https://llfc.club/articlepage?id=2OEQEc6p4k79cXsTr6dOVfZbo79
视频链接
本文仅作排查故障方法整理,其他不做赘述,相关处理方案可以看我博客其他文章和视频。
资源竞争
资源竞争大部分情况是逻辑错误,比如两个线程A和B同时修改互斥区域,互斥区域未加锁,这期间也可能造成崩溃,比如线程A删除了数据C,而线程B正在访问数据C,引发崩溃后大家不要慌,先看崩溃的堆栈信息,如果是指针显示为0xdddd之类的说明是访问了被删除的数据,那么我们排查删除的逻辑,或者屏蔽删除的逻辑看看会不会出问题,基本思路是
- 崩溃看堆栈信息,排查是不是野指针或者double free问题。
- 如果不是崩溃信息,数据混乱就查找修改数据的逻辑,或者屏蔽这个逻辑,看看是不是多线程造成的。
- 崩溃问题也可以通过屏蔽部分逻辑排查是不是多线程导致的。
- 在必要的逻辑区间增加日志,排查逻辑异常的上层原因。
这部分问题要结合实际工作去排查,慢慢熟悉这种思路以后就不陌生了。
死锁问题
多线程出现死锁问题是很头疼,现象不如内存崩溃或者资源竞争那么明显,表现给开发者的是一种卡死的现象。造成死锁的根本原因在于锁资源互相竞争,遇到这种问题要先梳理逻辑,找到互相引用的关键点。 我们通过代码仓库中concurrent文件夹day24-TroubleShoot 中deadlock.h演示
void deadlockdemo() {
std::mutex mtx;
int global_data = 0;
std::thread t1([&mtx, &global_data]() {
std::lock_guard<std::mutex> outer_lock(mtx);
global_data++;
std::async([&mtx, &global_data]() {
std::lock_guard<std::mutex> inner_lock(mtx);
global_data++;
std::cout << global_data << std::endl;
});
});
t1.join();
}
主函数调用这个函数,主进程无法退出。因为不是崩溃问题所以无法查看调用栈,对于这个问题,我们在关键位置打印日志,看看具体走到哪里出了问题。
void deadlockdemo() {
std::mutex mtx;
int global_data = 0;
std::thread t1([&mtx, &global_data]() {
std::cout << "begin lock outer_lock..." << std::endl;
std::lock_guard<std::mutex> outer_lock(mtx);
std::cout << "after lock outer_lock..." << std::endl;
global_data++;
std::async([&mtx, &global_data]() {
std::cout << "begin lock inner_lock..." << std::endl;
std::lock_guard<std::mutex> inner_lock(mtx);
std::cout << "after lock inner_lock..." << std::endl;
global_data++;
std::cout << global_data << std::endl;
std::cout << "unlock inner_lock..." << std::endl;
});
std::cout << "unlock outer_lock..." << std::endl;
});
t1.join();
}
日志输出
begin lock outer_lock...
after lock outer_lock...
begin lock inner_lock...
可以看到内部锁没有加成功。这种情况就是死锁了,再来分析原因,因为async会返回一个future,作为右值这个future会立即调用析构函数,析构函数内部会等待任务完成(并发编程已经从源码剖析了,这里不再赘述)。内部任务要加锁加不上,外部解不开锁因为async返回的future析构无法调用成功。这就是死锁的原因了。 修正,只要让future不立即调用析构即可,我们可以用变量接受future,这样析构就会延缓到解锁之后,变量可以放在最外层,这样变量不会触发析构。
void lockdemo() {
std::mutex mtx;
int global_data = 0;
std::future<void> future_res;
std::thread t1([&mtx, &global_data,&future_res]() {
std::cout << "begin lock outer_lock..." << std::endl;
std::lock_guard<std::mutex> outer_lock(mtx);
std::cout << "after lock outer_lock..." << std::endl;
global_data++;
future_res = std::async([&mtx, &global_data]() {
std::cout << "begin lock inner_lock..." << std::endl;
std::lock_guard<std::mutex> inner_lock(mtx);
std::cout << "after lock inner_lock..." << std::endl;
global_data++;
std::cout << global_data << std::endl;
std::cout << "unlock inner_lock..." << std::endl;
});
std::cout << "unlock outer_lock..." << std::endl;
});
t1.join();
}
程序输出
begin lock outer_lock...
after lock outer_lock...
unlock outer_lock...
begin lock inner_lock...
after lock inner_lock...
2
unlock inner_lock...
关于活锁,解决方式类似,在关键位置添加注释排查具体原因。
引用释放的变量
随着C++ 11 lambda表达式推出后,编程更方便了,但是引用释放的变量这个问题也随之而来。案例在day24-TroubleShoot文件夹deadlock.cpp中reference_invalid函数。
void reference_invalid()
{
class task_data {
public:
task_data(int i):_data(new int(i)){}
~task_data() { delete _data; }
int* _data;
};
std::queue<std::function<void()>> task_que;
for (int i = 0; i < 10; i++) {
task_data data(i);
task_que.push([&data]() {
(*data._data)++;
std::cout << "data is " << *data._data << std::endl;
});
}
auto res_future = std::async([&task_que]() {
for (;;) {
if (task_que.empty()) {
break;
}
auto& task = task_que.front();
task();
task_que.pop();
}
});
res_future.wait();
}
上述函数调用后输出的数值为
data is -572662307
data is 1349705340
data is -2147481856
data is -572662307
data is -572662307
data is -572662307
data is -572662307
data is -572662307
data is -572662307
data is -572662307
为什么数据变乱了呢?我们分析一下,这种多线程的逻辑问题就要通过加日志或者梳理逻辑排查了。异步任务里从任务队列弹出任务并执行,我们观察任务是一个lambda表达式,捕获的是task_data类型的引用,既然是引用就有生命周期,我们在将task放入队列时,task_data类型变量data为局部变量,此时还未失效,等离开循环的作用域调用data会调用析构函数,那么内部的数据就被释放了,所以之后线程异步访问时会出现乱码。
怎么改呢?我们在网络编程中介绍了一种思路,利用智能指针构造一个伪闭包逻辑,C++不像js,python,go等有闭包机制,但是我们可以通过智能指针增加引用计数,达到闭包效果。
void reference_sharedptr()
{
class task_data {
public:
task_data(int i) :_data(new int(i)) {}
~task_data() { delete _data; }
int* _data;
};
std::queue<std::function<void()>> task_que;
for (int i = 0; i < 10; i++) {
std::shared_ptr<task_data> taskptr = std::make_shared<task_data>(i);
task_que.push([taskptr]() {
(*( taskptr->_data))++;
std::cout << "data is " << *(taskptr->_data) << std::endl;
});
}
auto res_future = std::async([&task_que]() {
for (;;) {
if (task_que.empty()) {
break;
}
auto& task = task_que.front();
task();
task_que.pop();
}
});
res_future.wait();
}
再次运行输出正确。
浅拷贝
浅拷贝这个词对于C++开发者并不陌生,如果没有合理的内存管理机制,浅拷贝会造成很严重的内存崩溃问题。 看下面这个例子,同样在day24-TroubleShoot文件夹deadlock.cpp中
void shallow_copy(){
class task_data {
public:
task_data(int i) :_data(new int(i)) {}
~task_data() {
std::cout << "call task_data destruct" << std::endl;
delete _data;
}
int* _data;
};
task_data data1(1);
task_data data2 = std::move(data1);
}
上面这个例子运行会导致崩溃,我们看data1移动给data2后,二者在作用域结束时都进行析构。
因为我们没实现移动构造和拷贝构造,系统默认的移动构造执行拷贝构造,默认的拷贝构造是浅拷贝,所以data1和data2内部的_data引用同一块内存,他们析构的时候会造成二次析构。
读者可能觉得这个例子太简单,不会犯错,那我们看第二个例子
void shallow_copy2(){
class task_data {
public:
task_data(int i) :_data(new int(i)) {}
~task_data() {
std::cout << "call task_data destruct" << std::endl;
delete _data;
}
int* _data;
};
auto task_call = []() -> task_data {
task_data data(100);
return data;
};
task_call();
}
第二个例子中我们定义了一个lambda表达式task_call,返回task_data类型的对象。
关于返回局部对象,编译器有两种情况:
如果编译器支持返回值优化(Return Value Optimization, RVO),那么在返回局部对象时,编译器可能会通过返回值优化来避免执行移动构造函数。RVO 是一种编译器优化技术,可以避免对返回值进行拷贝或移动操作,直接将局部对象的值放置到调用者提供的空间中,从而减少了不必要的资源开销和性能消耗。
在 C++11 引入移动语义后,编译器有权将返回的局部对象视为右值,从而执行移动构造而非拷贝构造。
无论上述哪一种,都是将值返回,那么都会执行浅拷贝,局部变量随着作用域结束被释放,内部的内存_data被回收,而外部接收的返回值仍在引用_data,此时_data就是野指针。外部对象释放会造成二次析构,或者外部对象使用_data时也会引发野指针崩溃问题。
解决的方式就是实现拷贝构造和移动构造。
void normal_copy() {
class task_data {
public:
task_data(int i) :_data(new int(i)) {}
~task_data() {
std::cout << "call task_data destruct" << std::endl;
delete _data;
}
task_data(const task_data& src) {
_data = new int(*(src._data));
}
task_data(task_data&& src) {
_data = new int(*(src._data));
}
int* _data;
};
auto task_call = []() -> task_data {
task_data data(100);
return data;
};
task_call();
}
再次运行,看到调用两个析构函数,并且未崩溃
call task_data destruct
call task_data destruct
main exit
线程管控
多线程编程常遇到的一个问题就是线程管控。案例在day24-TroubleShoot文件夹deadlock.cpp中。
我们实现了一个生产者和消费者的管理类和一个用来控制退出的原子变量。
std::atomic<bool> b_stop = false;
class ProductConsumerMgr {
public:
ProductConsumerMgr(){
_consumer = std::thread([this]() {
while (!b_stop) {
std::unique_lock<std::mutex> lock(_mtx);
_consume_cv.wait(lock, [this]() {
if (_data_que.empty()) {
return false;
}
return true;
});
int data = _data_que.front();
_data_que.pop();
std::cout << "pop data is " << data << std::endl;
lock.unlock();
_producer_cv.notify_one();
}
});
_producer = std::thread([this]() {
int data = 0;
while (!b_stop) {
std::unique_lock<std::mutex> lock(_mtx);
_producer_cv.wait(lock, [this]() {
if (_data_que.size() > 100) {
return false;
}
return true;
});
_data_que.push(++data);
std::cout << "push data is " << data << std::endl;
lock.unlock();
_consume_cv.notify_one();
}
});
}
~ProductConsumerMgr(){
_producer.join();
_consumer.join();
}
private:
std::mutex _mtx;
std::condition_variable _consume_cv;
std::condition_variable _producer_cv;
std::queue<int> _data_que;
std::thread _consumer;
std::thread _producer;
};
- 生产者不断生产数据放入队列,消费者不断从队列消费数据。
- ProductConsumerMgr析构时等待生产者和消费者两个线程退出。
- b_stop用来控制线程退出。
我们实现捕获ctl+c以及关闭窗口信号的函数,然后将b_stop设置为true.
BOOL CtrlHandler(DWORD fdwCtrlType)
{
switch (fdwCtrlType)
{
// Handle the CTRL-C signal.
case CTRL_C_EVENT:
printf("Ctrl-C event\n\n");
b_stop = true;
return(TRUE);
// CTRL-CLOSE: confirm that the user wants to exit.
case CTRL_CLOSE_EVENT:
b_stop = true;
printf("Ctrl-Close event\n\n");
return(TRUE);
case CTRL_SHUTDOWN_EVENT:
b_stop = true;
printf("Ctrl-Shutdown event\n\n");
return FALSE;
default:
return FALSE;
}
}
void TestProducerConsumer()
{
SetConsoleCtrlHandler((PHANDLER_ROUTINE)CtrlHandler, TRUE);
ProductConsumerMgr mgr;
while (!b_stop) {
std::this_thread::sleep_for(std::chrono::milliseconds(10));
}
}
在主函数中启动TestProducerConsumer,生产者和消费者会不断工作,我们按下ctrl+c会中断程序,程序可以安全退出。在一般情况下没有问题,是不是意味着我们的程序足够健壮呢?
我们延缓生产者生产的效率,假设一个小时生产一个数据放入队列,此时Ctrl+c看看是否会中断程序
_producer = std::thread([this]() {
int data = 0;
while (!b_stop) {
std::this_thread::sleep_for(std::chrono::seconds(5));
std::unique_lock<std::mutex> lock(_mtx);
_producer_cv.wait(lock, [this]() {
if (_data_que.size() > 100) {
return false;
}
return true;
});
_data_que.push(++data);
std::cout << "push data is " << data << std::endl;
lock.unlock();
_consume_cv.notify_one();
}
});
生产者改为上述每5s产生一个数据,此时ctrl+c并不会中断程序,程序不会退出。
问题的根本在于条件竞争,当我们的生产者生产效率低时,队列为空,测试消费者线程处于挂起状态,ctrl+c虽然将停止信号设置为true,但是ProductConsumerMgr析构并不能执行完成,析构函数会等待两个线程退出,消费者线程不会退出,因为处于挂起状态了。
怎么办呢?我们可以在析构里通知两个线程退出即可。而且两个线程要增加唤醒后判断停止标记的逻辑。
~ProductConsumerMgr(){
_consume_cv.notify_one();
_producer_cv.notify_one();
_producer.join();
_consumer.join();
}
两个线程增加条件判断
ProductConsumerMgr(){
_consumer = std::thread([this]() {
while (!b_stop) {
std::unique_lock<std::mutex> lock(_mtx);
_consume_cv.wait(lock, [this]() {
if (b_stop) {
return true;
}
if (_data_que.empty()) {
return false;
}
return true;
});
if (b_stop) {
return ;
}
int data = _data_que.front();
_data_que.pop();
std::cout << "pop data is " << data << std::endl;
lock.unlock();
_producer_cv.notify_one();
}
});
_producer = std::thread([this]() {
int data = 0;
while (!b_stop) {
std::this_thread::sleep_for(std::chrono::seconds(5));
std::unique_lock<std::mutex> lock(_mtx);
_producer_cv.wait(lock, [this]() {
if (b_stop) {
return true;
}
if (_data_que.size() > 100) {
return false;
}
return true;
});
if (b_stop) {
return ;
}
_data_que.push(++data);
std::cout << "push data is " << data << std::endl;
lock.unlock();
_consume_cv.notify_one();
}
});
}
按下ctrl+c后,程序输出如下,并且正常退出
push data is 1
pop data is 1
Ctrl-C event
main exit
多线程之间协同工作以及安全退出是设计要考虑的事情。
混用智能指针和裸指针
有时候混用智能指针和裸指针,我们也会不小心delete一个交给只能指针管理的裸指针。单例在day24-TroubleShoot文件夹中ThreadSafeQue.h以及deadlock.cpp中。
之前我们为了让线程池从其他队列的尾部窃取任务,所以用双向链表实现了线程安全队列,并且实现了从尾部pop数据的方法。
bool try_steal(T& value) {
std::unique_lock<std::mutex> tail_lock(tail_mutex,std::defer_lock);
std::unique_lock<std::mutex> head_lock(head_mutex, std::defer_lock);
std::lock(tail_lock, head_lock);
if (head.get() == tail)
{
return false;
}
node* prev_node = tail->prev;
value = std::move(*(prev_node->data));
delete tail;
tail = prev_node;
tail->next = nullptr;
return true;
}
我们实现测试用例,一个线程push数据,一个线程从尾部pop数据,一个线程
void TestSteal() {
threadsafe_queue<int> que;
std::thread t1([&que]() {
int index = 0;
for (; ; ) {
index++;
que.push(index);
std::this_thread::sleep_for(std::chrono::milliseconds(200));
}
});
std::thread t3([&que]() {
for (; ; ) {
int value;
bool res = que.try_pop(value);
if (!res) {
std::this_thread::sleep_for(std::chrono::seconds(1));
continue;
}
std::cout << "pop out value is " << value << std::endl;
}
});
std::thread t2([&que]() {
for (; ; ) {
int value;
bool res = que.try_steal(value);
if (!res) {
std::this_thread::sleep_for(std::chrono::seconds(1));
continue;
}
std::cout << "steal out value is " << value << std::endl;
}
});
t1.join();
t2.join();
t3.join();
}
执行TestSteal时,程序崩溃。
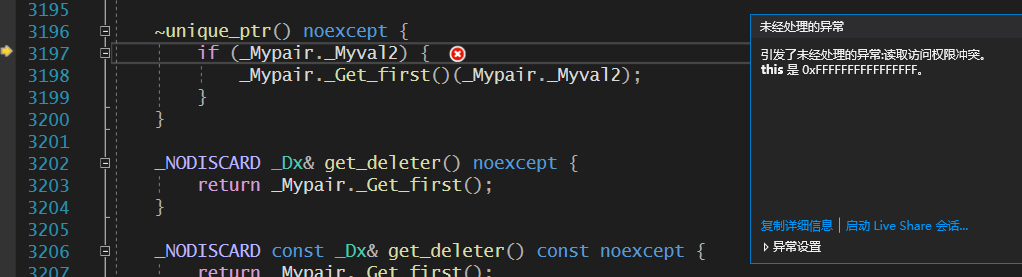
查看堆栈上层信息,崩溃在try_steal这个函数里了。
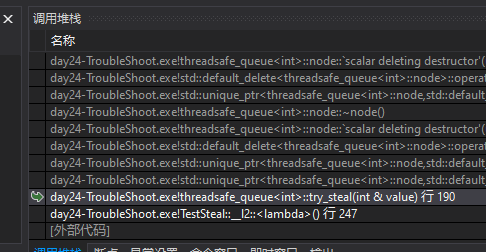
多线程排查问题时,先把最有嫌疑的线程屏蔽,我们把try_steal的线程屏蔽,发现没有引发崩溃。可以确定是try_steal导致。
我们看try_steal函数内部,涉及内存的有个delete tail, 我们将这个delete tail 注释,发现没问题了。可见是delete tail 出了问题,结合底层崩溃的信息是unique_ptr的析构函数,可以推断我们混用了裸指针和智能指针,很可能是delete了智能指针管理的内存,导致智能指针析构的时候又一次delete内存引发崩溃。 我们看下队列里节点的设计
struct node
{
std::shared_ptr<T> data;
std::unique_ptr<node> next;
node* prev;
};
std::mutex head_mutex;
std::unique_ptr<node> head;
std::mutex tail_mutex;
node* tail;
队列是通过node构造的链表,每个节点的next指针为智能指针指向下一个节点,head为std::unique_ptr<node>,tail虽然为node*类型的指针,但是是从智能指针get获取的,那么tail是不应该删除的。
解决的办法就是不用delete即可,pop 尾部节点后将新的尾部节点next指针设置为nullptr,这样就相当于对原tail所属的unique_ptr减少引用计数了。
总结
本文介绍了C++ 多线程以及内存等问题的排错思路和方法,感兴趣的可以看看源码。
源码链接 https://gitee.com/secondtonone1/boostasio-learn/tree/master/concurrent/day24-TroubleShoot
视频链接:
https://space.bilibili.com/271469206/channel/collectiondetail?sid=1623290