




变量计算
整型, 浮点,双精度等变量支持计算,所谓计算就是我们熟悉的
+,-,*,/,%等
void calculate(){
//整形变量支持计算,所谓计算就是我们熟悉的 `+` ,`-`,`*`,`/`,`%`等
int a = 10;
int b = 20;
std::cout << "a + b = " << a+b << std::endl;
std::cout << "a - b = " << a-b << std::endl;
std::cout << "a * b = " << a*b << std::endl;
std::cout << "a / b = " << a/b << std::endl;
std::cout << "a % b = " << a%b << std::endl;
//浮点型变量支持计算,所谓计算就是我们熟悉的 `+` ,`-`,`*`,`/`等
float c = 10.5;
float d = 20.3;
std::cout << "c + d = " << c+d << std::endl;
std::cout << "c - d = " << c-d << std::endl;
std::cout << "c * d = " << c*d << std::endl;
std::cout << "c / d = " << c/d << std::endl;
//浮点型变量支持计算,所谓计算就是我们熟悉的 `+` ,`-`,`*`,`/`等
double e = 10.5;
double f = 20.3;
std::cout << "e + f = " << e+f << std::endl;
std::cout << "e - f = " << e-f << std::endl;
std::cout << "e * f = " << e*f << std::endl;
std::cout << "e / f = " << e/f << std::endl;
}
ASCII码表
计算机中字符是用ASCII码记录的,ASCII码为128字符(0-127)分配了唯一的数字编码,包括英文字母(大小写)、数字、标点符号和一些控制字符(如换行、回车等)。
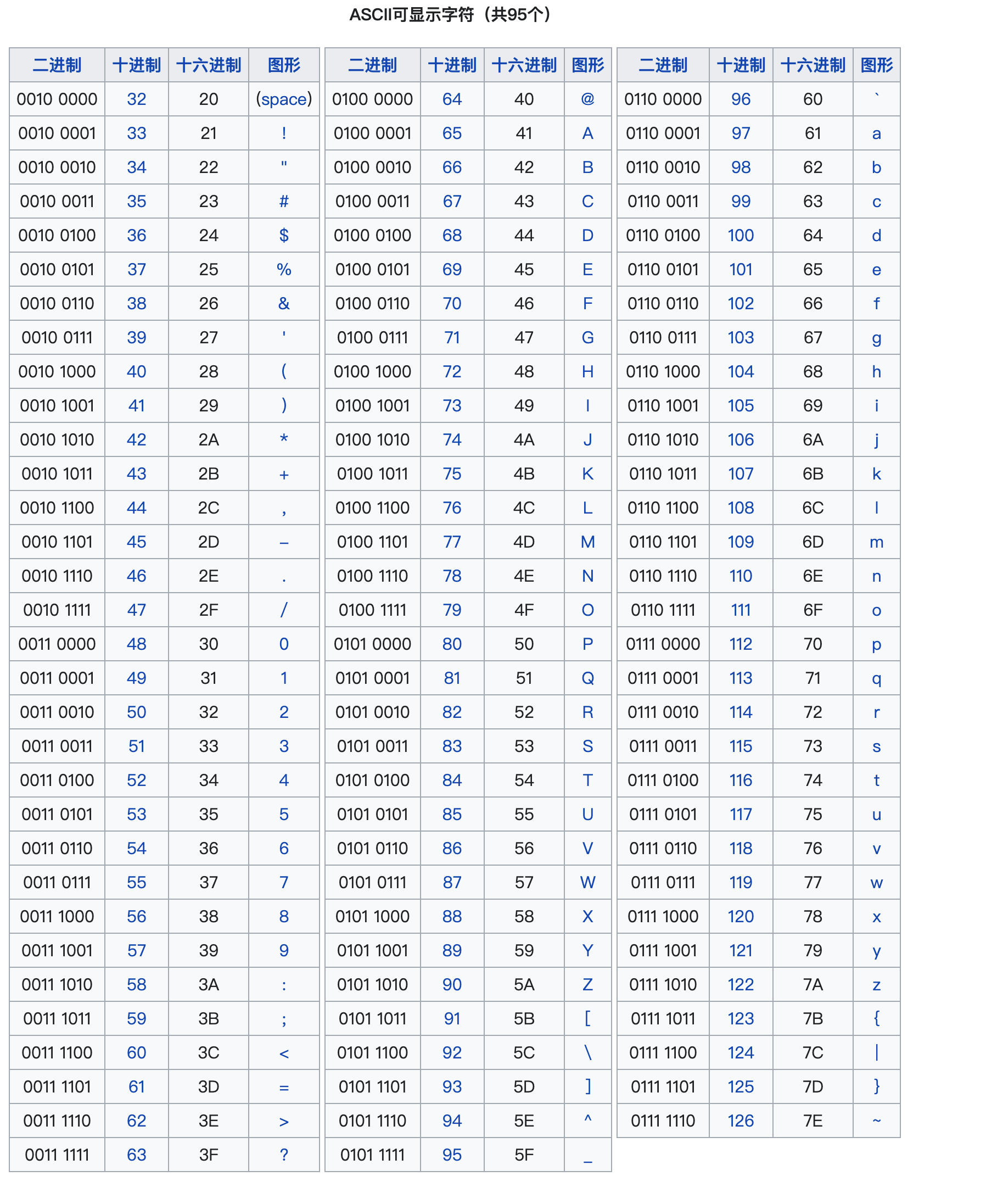
比如字符‘A’ 对应十进制的65,字符‘a'对应十进制的97.
所以字符也可以计算
//字符变量支持计算,所谓计算就是我们熟悉的 `+` ,`-`,`*`,`/`等
char g = 'a';
char h = 'b';
std::cout << "g + h = " << (int)(g+h) << std::endl;
std::cout << "g - h = " << (int)(g-h) << std::endl;
std::cout << "g * h = " << (int)(g*h) << std::endl;
std::cout << "g / h = " << (int)(g/h) << std::endl;
类型划分
各种数据类型可以支持转换,double, float,int, char 这种C++给我们提供的基本类型也叫做内置类型。
我们以后学习了结构体struct和class等自定义类型后,这些类型叫做复合类型,引用和指针也属于复合类型。
变量大小
前文提过变量是存储在存储单元中,那么计算机为不同的变量分配的大小也不一样, 可以通过sizeof计算类型的大小
void sizeofnum(){
std::cout << "Size of char: " << sizeof(char) << " bytes\n";
std::cout << "Size of int: " << sizeof(int) << " bytes\n";
std::cout << "Size of float: " << sizeof(float) << " bytes\n";
std::cout << "Size of double: " << sizeof(double) << " bytes\n";
std::cout << "Size of long long: " << sizeof(long long) << " bytes\n";
}
Size of char: 1 bytes
Size of int: 4 bytes
Size of float: 4 bytes
Size of double: 8 bytes
Size of long long: 8 bytes
类型转换
这里仅看下内置类型转换,C++会自动推导转换, 复合类型之后再介绍。
1B = 8bit 最大能表示127
char a = 100; // 100 是int类型,然后赋值给 char, int是四字节,char 是1字节,如果数字过大会损失精度。
int b = a; // char 转换为 int类型,不会损失数据
double c = b; // int 转换为 double(算数转换)
std::cout << "a = " << static_cast<int>(a) << ", b = " << b << ", c = " << c << std::endl;
// 注意:下面的转换可能会导致数据丢失
unsigned int d = -1; // int 转换为 unsigned int,导致数据丢失
std::cout << "d = " << d << std::endl; // 输出一个很大的数
变量作用域
在C++中,变量作用域(Scope)指的是程序中变量可以被访问的代码区域。作用域决定了变量的生命周期和可见性。
我可以解释几种常见的变量作用域类型:
- 全局作用域:在函数外部声明的变量具有全局作用域。它们可以在程序的任何地方被访问,但通常建议在需要时才使用全局变量,因为它们可能导致代码难以理解和维护。
- 局部作用域:在函数内部、代码块(如
if语句、for循环等)内部声明的变量具有局部作用域。它们只能在声明它们的代码块内被访问。一旦离开该代码块,这些变量就不再可见。 - 命名空间作用域:在命名空间中声明的变量(实际上是实体,如变量、函数等)具有命名空间作用域。它们只能在相应的命名空间内被直接访问,但可以通过使用命名空间的名称作为前缀来从外部访问。
- 类作用域:在类内部声明的成员变量和成员函数具有类作用域。成员变量和成员函数可以通过类的对象来访问,或者在某些情况下(如静态成员)可以通过类名直接访问。
- 块作用域:这是局部作用域的一个特例,指的是由大括号
{}包围的代码块内部声明的变量。这些变量只能在该代码块内被访问。
全局作用域
#include <iostream>
// 全局变量,具有全局作用域
int globalVar = 42;
void func() {
std::cout << "Inside func: globalVar = " << globalVar << std::endl;
}
int main() {
std::cout << "Inside main: globalVar = " << globalVar << std::endl;
func(); // 访问全局变量
return 0;
}
局部作用域
#include <iostream>
void func() {
// 局部变量,具有局部作用域
int localVar = 10;
std::cout << "Inside func: localVar = " << localVar << std::endl;
// localVar 在这里之后就不再可见
}
int main() {
// 尝试访问 localVar 会导致编译错误
// std::cout << "localVar = " << localVar << std::endl; // 错误
func(); // 局部变量仅在func函数内部可见
return 0;
}
命名空间作用域
#include <iostream>
// 定义一个命名空间
namespace MyNamespace {
// 命名空间内的变量,具有命名空间作用域
int namespaceVar = 20;
void printVar() {
std::cout << "Inside MyNamespace: namespaceVar = " << namespaceVar << std::endl;
}
int globalVar = 0;
}
namespace MyNamespace2 {
int globalVar = 0;
}
int main() {
// 使用命名空间前缀访问变量
std::cout << "Outside MyNamespace: namespaceVar = " << MyNamespace::namespaceVar << std::endl;
MyNamespace::printVar(); // 访问命名空间内的函数
return 0;
}
类作用域
#include <iostream>
class MyClass {
public:
// 成员变量,具有类作用域
int classVar;
// 成员函数,也可以访问类作用域内的成员变量
void printVar() {
std::cout << "Inside MyClass: classVar = " << classVar << std::endl;
}
};
int main() {
MyClass obj;
obj.classVar = 30; // 通过对象访问成员变量
obj.printVar(); // 访问成员函数
// 尝试直接访问 classVar 会导致编译错误
// std::cout << "classVar = " << classVar << std::endl; // 错误
return 0;
}
块作用域
#include <iostream>
void func() {
{
// 块内局部变量,具有块作用域
int blockVar = 5;
std::cout << "Inside block: blockVar = " << blockVar << std::endl;
// blockVar 在这个代码块之后就不再可见
}
// 尝试访问 blockVar 会导致编译错误
// std::cout << "blockVar = " << blockVar << std::endl; // 错误
}
int main() {
func(); // 访问块作用域变量仅在func函数内部的代码块内有效
return 0;
}
存储区域
在C++中,内存存储通常可以大致分为几个区域,这些区域根据存储的数据类型、生命周期和作用域来划分。这些区域主要包括:
- 代码区(Code Segment/Text Segment):
- 存储程序执行代码(即机器指令)的内存区域。这部分内存是共享的,只读的,且在程序执行期间不会改变。
- 举例说明:当你编译一个C++程序时,所有的函数定义、控制结构等都会被转换成机器指令,并存储在代码区。
- 全局/静态存储区(Global/Static Storage Area):
- 存储全局变量和静态变量的内存区域。这些变量在程序的整个运行期间都存在,但它们的可见性和生命周期取决于声明它们的作用域。
- 举例说明:全局变量(在函数外部声明的变量)和静态变量(使用
static关键字声明的变量,无论是在函数内部还是外部)都会存储在这个区域。
- 栈区(Stack Segment):
- 存储局部变量、函数参数、返回地址等的内存区域。栈是一种后进先出(LIFO)的数据结构,用于存储函数调用和自动变量。
- 举例说明:在函数内部声明的变量(不包括静态变量)通常存储在栈上。当函数被调用时,其参数和局部变量会被推入栈中;当函数返回时,这些变量会从栈中弹出,其占用的内存也随之释放。
- 堆区(Heap Segment):
- 由程序员通过动态内存分配函数(如
new和malloc)分配的内存区域。堆区的内存分配和释放是手动的,因此程序员需要负责管理内存,以避免内存泄漏或野指针等问题。 - 举例说明:当你使用
new操作符在C++中动态分配一个对象或数组时,分配的内存就来自堆区。同样,使用delete操作符可以释放堆区中的内存。
- 由程序员通过动态内存分配函数(如
- 常量区(Constant Area):
- 存储常量(如字符串常量、const修饰的全局变量等)的内存区域。这部分内存也是只读的,且通常在程序执行期间不会改变。
- 举例说明:在C++中,使用双引号括起来的字符串字面量通常存储在常量区。此外,使用
const关键字声明的全局变量,如果其值在编译时就已确定,也可能存储在常量区。
#include <iostream>
#include <cstring> // 用于strlen
// 全局变量,存储在全局/静态存储区
int globalVar = 10;
// 静态变量,也存储在全局/静态存储区,但仅在其声明的文件或函数内部可见
static int staticVar = 20;
void func() {
// 局部变量,存储在栈区
int localVar = 30;
// 静态局部变量,虽然声明在函数内部,但存储在全局/静态存储区,且只在第一次调用时初始化
static int staticLocalVar = 40;
std::cout << "Inside func:" << std::endl;
std::cout << "localVar = " << localVar << std::endl;
std::cout << "staticLocalVar = " << staticLocalVar << std::endl;
// 尝试通过动态内存分配在堆区分配内存
int* heapVar = new int(50);
std::cout << "heapVar = " << *heapVar << std::endl;
// 释放堆区内存(重要:实际使用中不要忘记释放不再使用的堆内存)
delete heapVar;
}
int main() {
// 访问全局变量
std::cout << "Inside main:" << std::endl;
std::cout << "globalVar = " << globalVar << std::endl;
std::cout << "staticVar = " << staticVar << std::endl; // 注意:staticVar在外部不可见(除非在同一个文件中或通过特殊方式)
// 调用函数,展示栈区和堆区的使用
func();
// 字符串常量通常存储在常量区,但直接访问其内存地址并不是标准C++的做法
// 这里我们仅通过指针来展示其存在
const char* strConst = "Hello, World!";
// 注意:不要尝试修改strConst指向的内容,因为它是只读的
std::cout << "strConst = " << strConst << std::endl;
// 尝试获取字符串常量的长度(这不会修改常量区的内容)
std::cout << "Length of strConst = " << strlen(strConst) << std::endl;
return 0;
}
在这个示例中,我使用了全局变量、静态变量、局部变量、静态局部变量以及通过new操作符在堆上分配的内存来展示不同内存区域的使用。同时,我也提到了字符串常量,但请注意,直接访问其内存地址并不是C++编程中的标准做法,因为字符串常量通常是只读的,并且其存储位置取决于编译器和操作系统的实现。
另外,请注意,我在func函数中分配了堆内存并通过delete操作符释放了它。这是管理堆内存时的一个重要实践,以避免内存泄漏。然而,在实际应用中,更复杂的内存管理策略(如智能指针)可能更为合适。
当您编译这个程序时,编译器会将main函数和func函数的代码转换成机器指令,并将这些指令存储在可执行文件的代码区中(尽管实际上是在磁盘上的可执行文件中,但在程序运行时,操作系统会将这些指令加载到内存的代码区中)。然后,当您运行这个程序时,CPU会从内存的代码区中读取这些指令并执行它们。
程序编译过程
C++程序的编译过程是一个相对复杂但有序的过程,它涉及将高级语言(C++)代码转换为机器可以执行的低级指令。在这个过程中,通常会生成几个中间文件,包括.i(预处理文件)、.s(汇编文件)和.o(目标文件或对象文件)。下面是这个过程的详细解释:
1. 预处理(Preprocessing)
- 输入:C++源代码文件(通常以
.cpp或.cxx为后缀)。 - 处理:预处理器(通常是
cpp)读取源代码文件,并对其进行宏展开、条件编译、文件包含(#include)等处理。 - 输出:生成预处理后的文件,通常具有
.i后缀(尽管这个步骤可能不是所有编译器都会自动生成.i文件,或者可能需要特定的编译器选项来生成)。
2. 编译(Compilation)
- 输入:预处理后的文件(如果有的话,否则直接是源代码文件)。
- 处理:编译器(如
g++、clang++等)将预处理后的文件或源代码文件转换为汇编语言代码。这个步骤是编译过程的核心,它执行词法分析、语法分析、语义分析、中间代码生成、代码优化等任务。 - 输出:生成汇编文件,通常具有
.s或.asm后缀。
3. 汇编(Assembly)
- 输入:汇编文件。
- 处理:汇编器(如
as、gas等)将汇编语言代码转换为机器语言指令(即目标代码),但这些指令仍然是针对特定架构的,并且尚未被链接成可执行文件。 - 输出:生成目标文件(或对象文件),通常具有
.o、.obj或.out后缀。
4. 链接(Linking)
- 输入:一个或多个目标文件,以及可能需要的库文件(如C++标准库)。
- 处理:链接器(如
ld、lld等)将目标文件和库文件合并成一个可执行文件或库文件。在这个过程中,链接器会解决外部符号引用(即函数和变量的调用),并将它们链接到正确的地址。 - 输出:生成可执行文件(在Unix-like系统中通常是
.out、.exe或没有特定后缀,在Windows系统中是.exe)。
我们将代码的CMakeList中设置编译选项,保存临时文件
set(CMAKE_CXX_FLAGS "${CMAKE_CXX_FLAGS} -save-temps=obj")
set(CMAKE_C_FLAGS "${CMAKE_CXX_FLAGS} -save-temps=obj")
点击Clion中的build,可以看到目录中生成了临时文件,包括
.i 文件表示预处理文件
.s(汇编文件)
.o(目标文件或对象文件)
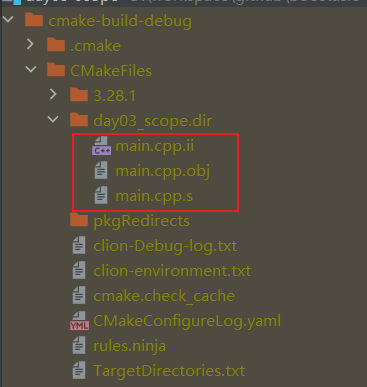
总结
.i文件是预处理后的文件,包含了所有宏展开、条件编译和文件包含的结果。.s文件是汇编文件,包含了将C++代码转换为汇编语言后的结果。.o文件是目标文件或对象文件,包含了汇编器生成的机器语言指令,但尚未被链接成可执行文件。
这些文件在编译过程中扮演了重要的角色,帮助开发者理解和调试代码,同时也是编译链中不可或缺的一部分。不过,值得注意的是,并非所有编译器都会默认生成.i和.s文件,这可能需要特定的编译器选项来启用。
赞赏
感谢支持
