




简介
本文介绍如何通过互斥锁和条件变量等并发机制实现线程安全的队列和栈容器。
线程安全的栈
实现一个线程安全的栈,我们能想到的是基于锁控制push和pop操作,比如下面的逻辑
#include <exception>
#include <mutex>
#include <stack>
#include <condition_variable>
struct empty_stack : std::exception
{
const char* what() const throw();
};
template<typename T>
class threadsafe_stack
{
private:
std::stack<T> data;
mutable std::mutex m;
public:
threadsafe_stack() {}
threadsafe_stack(const threadsafe_stack& other)
{
std::lock_guard<std::mutex> lock(other.m);
data = other.data;
}
threadsafe_stack& operator=(const threadsafe_stack&) = delete;
void push(T new_value)
{
std::lock_guard<std::mutex> lock(m);
data.push(std::move(new_value)); // ⇽-- - 1
}
std::shared_ptr<T> pop()
{
std::lock_guard<std::mutex> lock(m);
if (data.empty()) throw empty_stack(); // ⇽-- - 2
std::shared_ptr<T> const res(
std::make_shared<T>(std::move(data.top()))); // ⇽-- - 3
data.pop(); // ⇽-- - 4
return res;
}
void pop(T& value)
{
std::lock_guard<std::mutex> lock(m);
if (data.empty()) throw empty_stack();
value = std::move(data.top()); // ⇽-- - 5
data.pop(); // ⇽-- - 6
}
bool empty() const
{
std::lock_guard<std::mutex> lock(m);
return data.empty();
}
};
我们实现了push操作和pop操作
- push操作里加锁,然后将数据通过
std::move的方式移动放入stack中。我们思考如果1处因为机器内存不足push导致异常,此种情况并不会对栈已有的数据产生危险。
但是vector容器大家要考虑,因为vector存在内存不足时将数据拷贝转移到新空间的过程。那么对于vector这种动态扩容的容器该如何保证容器内数据在移动过程中出现了异常仍能不丢失呢?
我想到的一个方式就是管理vector的capacity,每次push的时候要判断一下vector的size和capacity是否相等,如果相等则手动扩容并将数据转移到新的vector,再释放旧有的vector。
但是同样会存在一个问题就是会造成内存溢出,因为vector的capacity会随着数据增加而增加,当vector中没有数据的时候capacity仍然很大。这种方式也可以通过swap的方式将当前大容量的vector和一个空的vector做交换,快速清空内存。这些操作和思路需结合实际开发情况而定。
pop提供了两个版本,一个是返回智能指针一个是返回bool类型,这两种我们分析,比如3处和4处也很可能因为内存不足导致构造智能指针失败,或者5处赋值失败,这种情况下抛出异常并不会影响栈内数据,因为程序没走到4和6处就抛出异常了。
pop函数内部判断栈是否空,如果为空则抛出异常,这种情况我们不能接受,异常是用来处理和预判突发情况的,对于一个栈为空这种常见现象,仅需根据返回之后判断为空再做尝试或放弃出栈即可。
为了解决栈为空就抛出异常的问题,我们可以做如下优化
template<typename T>
class threadsafe_stack_waitable
{
private:
std::stack<T> data;
mutable std::mutex m;
std::condition_variable cv;
public:
threadsafe_stack_waitable() {}
threadsafe_stack_waitable(const threadsafe_stack_waitable& other)
{
std::lock_guard<std::mutex> lock(other.m);
data = other.data;
}
threadsafe_stack_waitable& operator=(const threadsafe_stack_waitable&) = delete;
void push(T new_value)
{
std::lock_guard<std::mutex> lock(m);
data.push(std::move(new_value)); // ⇽-- - 1
cv.notify_one();
}
std::shared_ptr<T> wait_and_pop()
{
std::unique_lock<std::mutex> lock(m);
cv.wait(lock, [this]()
{
if(data.empty())
{
return false;
}
return true;
}); // ⇽-- - 2
std::shared_ptr<T> const res(
std::make_shared<T>(std::move(data.top()))); // ⇽-- - 3
data.pop(); // ⇽-- - 4
return res;
}
void wait_and_pop(T& value)
{
std::unique_lock<std::mutex> lock(m);
cv.wait(lock, [this]()
{
if (data.empty())
{
return false;
}
return true;
});
value = std::move(data.top()); // ⇽-- - 5
data.pop(); // ⇽-- - 6
}
bool empty() const
{
std::lock_guard<std::mutex> lock(m);
return data.empty();
}
bool try_pop(T& value)
{
std::lock_guard<std::mutex> lock(m);
if(data.empty())
{
return false;
}
value = std::move(data.top());
data.pop();
return true;
}
std::shared_ptr<T> try_pop()
{
std::lock_guard<std::mutex> lock(m);
if(data.empty())
{
return std::shared_ptr<T>();
}
std::shared_ptr<T> res(std::make_shared<T>(std::move(data.top())));
data.pop();
return res;
}
};
我们将pop优化为四个版本,四个版本又可以分为两个大类,两个大类分别为try_pop版本和wait_and_pop版本。
try_pop版本不阻塞等待队列有数据才返回,而是直接返回,try_pop又有两个版本,分别返回bool值和指针值。如果队列为空返回false或者空指针。
wait_and_pop版本阻塞等待队列有数据才返回,同样有两个版本,分别返回bool值和指针值。
但是上面的代码我们分析,假设此时栈为空,有一个线程A从队列中消费数据,调用wait_and_pop挂起, 此时另一个线程B向栈中放入数据调用push操作,notify一个线程消费队列中的数据。
此时A从wait_and_pop唤醒,但是在执行3或者5处时,因为内存不足引发了异常,我们之前分析过,即使引发异常也不会影响到栈内数据,所以对于栈的数据来说是安全的,但是线程A异常后,其他线程无法从队列中消费数据,除非线程B再执行一次push。因为我们采用的是notify_one的方式,所以仅有一个线程被激活,如果被激活的线程异常了,就不能保证该数据被其他线程消费了,解决这个问题,可以采用几个方案。
wai_and_pop失败的线程修复后再次取一次数据。- 将
notify_one改为notify_all,这样能保证通知所有线程。但是notify_all将导致所有线程竞争,并不可取。 - 我们可以通过栈存储智能指针的方式进行,因为智能指针在赋值的时候不会引发异常。
稍后我们提供的线程安全队列的版本使用的就是第三种优化。
线程安全队列
队列和栈最大的不同就是队列为先入先出,有了线程安全的栈的开发思路,我们很快实现一个支持线程安全的队列
#include <mutex>
#include <queue>
template<typename T>
class threadsafe_queue
{
private:
mutable std::mutex mut;
std::queue<T> data_queue;
std::condition_variable data_cond;
public:
threadsafe_queue()
{}
void push(T new_value)
{
std::lock_guard<std::mutex> lk(mut);
data_queue.push(std::move(new_value));
data_cond.notify_one(); //⇽-- - ①
}
void wait_and_pop(T& value) //⇽-- - ②
{
std::unique_lock<std::mutex> lk(mut);
data_cond.wait(lk, [this] {return !data_queue.empty(); });
value = std::move(data_queue.front());
data_queue.pop();
}
std::shared_ptr<T> wait_and_pop() // ⇽-- - ③
{
std::unique_lock<std::mutex> lk(mut);
data_cond.wait(lk, [this] {return !data_queue.empty(); }); // ⇽-- - ④
std::shared_ptr<T> res(
std::make_shared<T>(std::move(data_queue.front())));
data_queue.pop();
return res;
}
bool try_pop(T& value)
{
std::lock_guard<std::mutex> lk(mut);
if (data_queue.empty())
return false;
value = std::move(data_queue.front());
data_queue.pop();
return true;
}
std::shared_ptr<T> try_pop()
{
std::lock_guard<std::mutex> lk(mut);
if (data_queue.empty())
return std::shared_ptr<T>(); //⇽-- - ⑤
std::shared_ptr<T> res(
std::make_shared<T>(std::move(data_queue.front())));
data_queue.pop();
return res;
}
bool empty() const
{
std::lock_guard<std::mutex> lk(mut);
return data_queue.empty();
}
};
关于异常情况的分析和栈一样,上面的队列版本不存在异常导致数据丢失的问题。但是同样面临线程执行wait_and_pop时如果出现了异常,导致数据被滞留在队列中,其他线程也无法被唤醒的情况。
为了解决这种情况,我们前文提到了采用智能指针的方式,重新实现一下线程安全队列
template<typename T>
class threadsafe_queue_ptr
{
private:
mutable std::mutex mut;
std::queue<std::shared_ptr<T>> data_queue;
std::condition_variable data_cond;
public:
threadsafe_queue_ptr()
{}
void wait_and_pop(T& value)
{
std::unique_lock<std::mutex> lk(mut);
data_cond.wait(lk, [this] {return !data_queue.empty(); });
value = std::move(*data_queue.front()); //⇽-- - 1
data_queue.pop();
}
bool try_pop(T& value)
{
std::lock_guard<std::mutex> lk(mut);
if (data_queue.empty())
return false;
value = std::move(*data_queue.front()); // ⇽-- - 2
data_queue.pop();
return true;
}
std::shared_ptr<T> wait_and_pop()
{
std::unique_lock<std::mutex> lk(mut);
data_cond.wait(lk, [this] {return !data_queue.empty(); });
std::shared_ptr<T> res = data_queue.front(); // ⇽-- - 3
data_queue.pop();
return res;
}
std::shared_ptr<T> try_pop()
{
std::lock_guard<std::mutex> lk(mut);
if (data_queue.empty())
return std::shared_ptr<T>();
std::shared_ptr<T> res = data_queue.front(); // ⇽-- - 4
data_queue.pop();
return res;
}
void push(T new_value)
{
std::shared_ptr<T> data(
std::make_shared<T>(std::move(new_value))); // ⇽-- - 5
std::lock_guard<std::mutex> lk(mut);
data_queue.push(data);
data_cond.notify_one();
}
bool empty() const
{
std::lock_guard<std::mutex> lk(mut);
return data_queue.empty();
}
};
在5处,我们push数据时需要先构造智能指针,如果构造的过程失败了也就不会push到队列中,不会污染队列中的数据。
2,3处和4,5处我们仅仅时将智能指针取出来赋值给一个新的智能指针并返回。关于智能指针的赋值不会引发异常这一点在C++并发编程中提及,这一点我觉得有些存疑,我觉得书中表述的意思应该是指针在64位机器占用8个字节,所有智能指针共享引用计数所以在复制时仅为8字节开销,降低了内存消耗。
所以推荐大家存储数据放入容器中时尽量用智能指针,这样能保证复制和移动过程中开销较小,也可以实现一定意义的数据共享。
但是我们分析上面的代码,队列push和pop时采用的是一个mutex,导致push和pop等操作串行化,我们要考虑的是优化锁的精度,提高并发,那有什么办法吗?
我们分析,队列和栈最本质的区别是队列是首尾操作。我们可以考虑将push和pop操作分化为分别对尾和对首部的操作。对首和尾分别用不同的互斥量管理就可以实现真正意义的并发了。
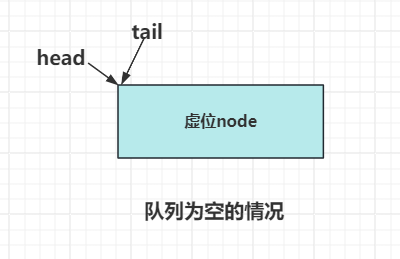
我们引入虚位节点的概念,表示一个空的节点,没有数据,是一个无效的节点,初始情况下,队列为空,head和tail节点都指向这个虚位节点。
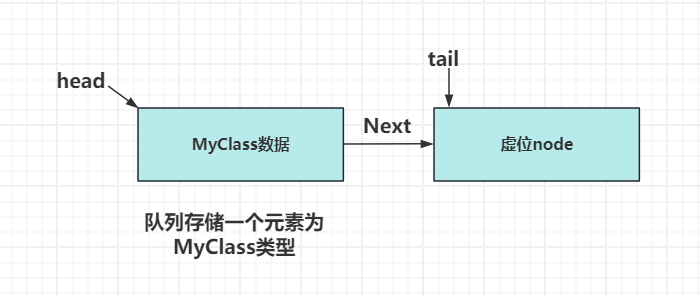
当我们push一个数据,比如为MyClass类型的数据后,tail向后移动一个位置,并且仍旧指向这个虚位节点。
如下图
接下来我们实现这个版本的并发安全队列
template<typename T>
class threadsafe_queue_ht
{
private:
struct node
{
std::shared_ptr<T> data;
std::unique_ptr<node> next;
};
std::mutex head_mutex;
std::unique_ptr<node> head;
std::mutex tail_mutex;
node* tail;
std::condition_variable data_cond;
node* get_tail()
{
std::lock_guard<std::mutex> tail_lock(tail_mutex);
return tail;
}
std::unique_ptr<node> pop_head()
{
std::unique_ptr<node> old_head = std::move(head);
head = std::move(old_head->next);
return old_head;
}
std::unique_lock<std::mutex> wait_for_data()
{
std::unique_lock<std::mutex> head_lock(head_mutex);
data_cond.wait(head_lock,[&] {return head.get() != get_tail(); }); //5
return std::move(head_lock);
}
std::unique_ptr<node> wait_pop_head()
{
std::unique_lock<std::mutex> head_lock(wait_for_data());
return pop_head();
}
std::unique_ptr<node> wait_pop_head(T& value)
{
std::unique_lock<std::mutex> head_lock(wait_for_data());
value = std::move(*head->data);
return pop_head();
}
std::unique_ptr<node> try_pop_head()
{
std::lock_guard<std::mutex> head_lock(head_mutex);
if (head.get() == get_tail())
{
return std::unique_ptr<node>();
}
return pop_head();
}
std::unique_ptr<node> try_pop_head(T& value)
{
std::lock_guard<std::mutex> head_lock(head_mutex);
if (head.get() == get_tail())
{
return std::unique_ptr<node>();
}
value = std::move(*head->data);
return pop_head();
}
public:
threadsafe_queue_ht() : // ⇽-- - 1
head(new node), tail(head.get())
{}
threadsafe_queue_ht(const threadsafe_queue_ht& other) = delete;
threadsafe_queue_ht& operator=(const threadsafe_queue_ht& other) = delete;
std::shared_ptr<T> wait_and_pop() // <------3
{
std::unique_ptr<node> const old_head = wait_pop_head();
return old_head->data;
}
void wait_and_pop(T& value) // <------4
{
std::unique_ptr<node> const old_head = wait_pop_head(value);
}
std::shared_ptr<T> try_pop()
{
std::unique_ptr<node> old_head = try_pop_head();
return old_head ? old_head->data : std::shared_ptr<T>();
}
bool try_pop(T& value)
{
std::unique_ptr<node> const old_head = try_pop_head(value);
return old_head;
}
bool empty()
{
std::lock_guard<std::mutex> head_lock(head_mutex);
return (head.get() == get_tail());
}
void push(T new_value) //<------2
{
std::shared_ptr<T> new_data(
std::make_shared<T>(std::move(new_value)));
std::unique_ptr<node> p(new node);
node* const new_tail = p.get();
std::lock_guard<std::mutex> tail_lock(tail_mutex);
tail->data = new_data;
tail->next = std::move(p);
tail = new_tail;
}
};
node为节点类型,包含data和next两个成员。 data为智能指针类型存储T类型的数据。next为指向下一个节点的智能指针,以此形成链表。
上述代码我们的head是一个node类型的智能指针。而tail为node类型的普通指针,读者也可以用智能指针。
在1处构造函数那里,我们将head和tail初始指向的位置设置为虚位节点。
在2 处我们push数据的时候先构造T类型的智能指针存储数据new_data,然后我们构造了一个新的智能指针p, p取出裸指针就是新的虚位节点new_tail,我们将new_data赋值给现在的尾节点,并且让尾节点的next指针指向p, 然后将tail更新为我们新的虚位节点。
3,4处都是wait_and_pop的不同版本,内部调用了wait_pop_head,wait_pop_head内部先调用wait_for_data判断队列是否为空,这里判断是否为空主要是判断head是否指向虚位节点。如果不为空则返回unique_lock,我们显示的调用了move操作,返回unique_lock仍保留对互斥量的锁住状态。
回到wait_pop_head中,接下来执行pop_head将数据pop出来。
值得注意的是get_tail()返回tail节点,那么我们思考如果此时有多个线程push数据,tail节点已经变化了,我们此时在5处的判断可能是基于push之前的tail信息,但是不影响逻辑,因为如果head和tail相等则线程挂起,等待通知,如果不等则继续执行,push操作只会将tail向后移动不会导致逻辑问题。
pop_head中我们将head节点移动给一个old_head变量,然后将old_head的next节点更新为新的head。这里我觉得可以简化写为head=head->next.
测试结果详见源码
总结
本文介绍了线程安全情况下栈和队列的实现方式
源码链接:
https://gitee.com/secondtonone1/boostasio-learn/tree/master/concurrent/day14-ThreadSafeContainer
视频链接
https://space.bilibili.com/271469206/channel/collectiondetail?sid=1623290