




前情回顾
前文我们完成了日志采集系统的日志文件监控,配置文件热更新,协程异常检测和保活机制。
本节目标
本节加入kafka消息队列,kafka前文也介绍过了,可以对消息进行排队,解耦合和流量控制的作用,为什么一定要用kafka呢?主要原因就是在日志高并发读取后,如果直接将消息发给前端或者写入数据库,会造成崩溃或者卡死。kafka可以对消息进行排队和减轻压力,这样无论以后将这些消息录入数据库也好,传给前端分析也好,都能保证系统稳定性。代码我们也写过和测试了,只需要将之前写好的kafka读写消息代码整合过来即可。
主函数创建kafka生产者
在主函数中创建kafkaProducer,然后在defer中回收该资源。我们将该producer传递给每个监控日志的协程中,当日志有修改,就通过producer将修改的信息写入kafka,用kafka排队和缓存,可以提高稳定性,减少流量高峰。
func main() {
//省略...
kafkaProducer := &kafkaqueue.ProducerKaf{Producer: producer}
configMgr = make(map[string]*logconfig.ConfigData)
keyChan := make(chan string, KEYCHANSIZE)
ConstructMgr(configPaths, keyChan, kafkaProducer)
defer func() {
mainOnce.Do(func() {
//省略...
kafkaProducer.Producer.Close()
})
}()
for {
select {
case pathData, ok := <-pathChan:
if !ok {
return
}
//省略...
for conkey, conval := range pathDataNew {
oldval, ok := configMgr[conkey]
if !ok {
//省略...
go logtailf.WatchLogFile(configData.ConfigKey, configData.ConfigValue,
ctx, keyChan, kafkaProducer)
continue
}
if oldval.ConfigValue != conval.(string) {
//省略...
go logtailf.WatchLogFile(conkey, conval.(string),
ctx, keyChan, kafkaProducer)
continue
}
}
case keystr := <-keyChan:
val, ok := configMgr[keystr]
if !ok {
continue
}
//省略...
go logtailf.WatchLogFile(keystr, val.ConfigValue,
ctxcover, keyChan, kafkaProducer)
}
}
}
WatchLogFile函数携带了该producer。有人会问多个协程共享producer是否会出问题?我查看了Producer发送消息的源码
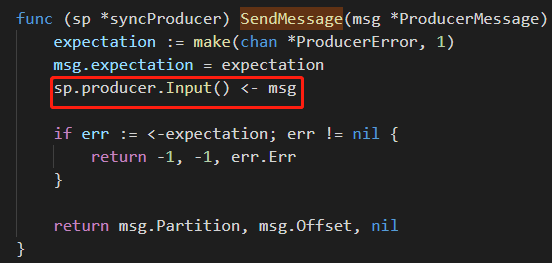 红框中使用了chan传递数据,所以在多个协程调用producer的发送函数是没问题的。
红框中使用了chan传递数据,所以在多个协程调用producer的发送函数是没问题的。
监控协程写入kafka消息
当日志新增时,我们在监控日志的协程向kafka写入消息
func WatchLogFile(pathkey string, datapath string, ctx context.Context, keychan chan<- string, kafProducer *kafkaqueue.ProducerKaf) {
//省略逻辑...
for true {
select {
case msg, ok := <-tailFile.Lines:
//省略逻辑...
kafProducer.PutIntoKafka(pathkey, msg.Text)
case <-ctx.Done():
fmt.Println("receive main gouroutine exit msg")
fmt.Println("watch log file ", pathkey, " goroutine exited")
return
}
}
}
封装kafkaProducer
上述代码中调用的kafkaProducer是我自己封装的,其实就是组合了原生的kafka生产者,并且封装了发送函数
func CreateKafkaProducer() (sarama.SyncProducer, error) {
config := sarama.NewConfig()
// 等待服务器所有副本都保存成功后的响应
config.Producer.RequiredAcks = sarama.WaitForAll
// 随机的分区类型:返回一个分区器,该分区器每次选择一个随机分区
config.Producer.Partitioner = sarama.NewRandomPartitioner
// 是否等待成功和失败后的响应
config.Producer.Return.Successes = true
// 使用给定代理地址和配置创建一个同步生产者
producer, err := sarama.NewSyncProducer([]string{"localhost:9092"}, config)
if err != nil {
fmt.Println("create producer failed, ", err.Error())
return nil, err
}
fmt.Println("create kafka producer success")
return producer, nil
}
上面的函数返回了原生的kafka生产者接口,接下来我们封装这个原生接口,然后编写了写入kafka的方法。
type ProducerKaf struct {
Producer sarama.SyncProducer
}
func (p *ProducerKaf) PutIntoKafka(keystr string, valstr string) {
//构建发送的消息,
msg := &sarama.ProducerMessage{
Topic: "logcatchsys",
Key: sarama.StringEncoder(keystr),
Value: sarama.StringEncoder(valstr),
}
partition, offset, err := p.Producer.SendMessage(msg)
if err != nil {
fmt.Println("Send message Fail")
fmt.Println(err.Error())
}
fmt.Printf("Partition = %d, offset=%d, msgvalue=%s \n", partition, offset, valstr)
}
启动kafka测试
我们先启动zookeeper和kafka zookeeper进入bin文件夹点击zkServer.cmd即可启动 kafka启动使用如下命令
.\bin\windows\kafka-server-start.bat .\config\server.properties
然后我们创建主题logcatchsys
.\bin\windows\kafka-topics.bat --create --zookeeper localhost:2181 --replication-factor 1 --partitions 16 --topic logcatchsys
这样我们为主题logcatchsys创建了16个分区。 接下来我们启动消费者
.\bin\windows\kafka-console-consumer.bat --bootstrap-server localhost:9092 --topic logcatchsys --from-beginning
然后我们启动我们的采集系统和测死脚本,看到如下
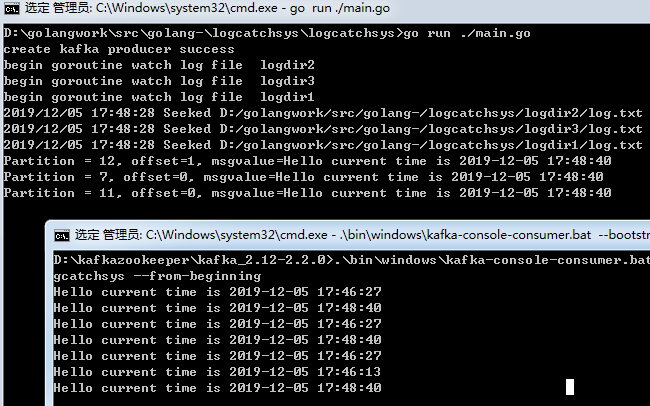 可以看到当日志文件不断被写入时,我们的采集系统会将修改的内容实时监控并写入kafka队列,然后kafka消费者从队列中取出这些消息。
可以看到当日志文件不断被写入时,我们的采集系统会将修改的内容实时监控并写入kafka队列,然后kafka消费者从队列中取出这些消息。
总结
目前完成了日志采集系统所有功能的开发和测试,包括配置文件的热更新,监控协程的自动关闭和启动,异常修复和自启动,日志消息的监听,
kafka消息的读写等。但这并不是终点,只是一个起点,以后会配合前端开发不断完善,目前先告一段落。
源码下载
https://github.com/secondtonone1/golang-/tree/master/logcatchsys
感谢关注公众号
