




抓取准备
今天是10月24日,祝所有程序员节日快乐。今天打算写个爬虫抓取3DMGAME论坛美女cosplay壁纸。 论坛首页网址为https://www.3dmgame.com/tu_53_1/ 我们点击其中一个图集,然后网页跳转,看下源码
<div class="dg-wrapper">
<a data-src = "/uploads/images/thumbpicfirst/20190730/1564452665_126346.jpg">
<div class="img"><img src="https://img.3dmgame.com/uploads/images/thumbpicfirst/20190730/1564452665_126346.jpg"></div>
<div class="miaoshu">
<p></p>
<div class="num"><i></i> /<u></u></div>
</div>
</a>
<a data-src = "/uploads/images/thumbpicfirst/20190730/1564452665_242197.jpg">
<div class="img"><img src="https://img.3dmgame.com/uploads/images/thumbpicfirst/20190730/1564452665_242197.jpg"></div>
<div class="miaoshu">
<p></p>
<div class="num"><i></i> /<u></u></div>
</div>
</a>
网址是静态的,我们直接提取其中的图片链接再下载即可。 抓取网页采用的是python的requests库,直接发送http请求即可。收到回包后,通过BeautifulSoup提炼其中图片地址再次下载即可。 另外我们的界面用的是python自带的Tinker编写的。
代码实现
实现线程装饰器
def thread_run(func):
def wraper(*args, **kwargs):
t = threading.Thread(target=func, args=args, kwargs=kwargs)
t.daemon = True
t.start()
return wraper
封装了一个装饰器,启动线程并调用传入的函数。
我们实现了DownloadFrame类
类里实现如下方法
def prepare(self, downloadlinks):
self.flag = True
self.downloadlinks = downloadlinks
self.base_url = self.downloadlinks
fail = 0
try:
url = self.base_url
result = requests.get(url, headers=HEADERS,timeout=10)
restxt = result.content.decode('UTF-8')
soup = BeautifulSoup(restxt,'lxml')
titles = soup.select('div .bt')
if titles is None or len(titles)==0:
print("html page res not found ! \n")
return
title = re.split(r'[;,\s]',titles[0].text)[0]
curdir = os.path.dirname(os.path.abspath(__file__))
picpath = os.path.join(curdir,title)
if not os.path.exists(picpath):
os.mkdir(picpath)
print(picpath)
imglist = soup.select('.dg-wrapper img')
if imglist is None or len(imglist)==0:
print("html page res not found ! \n")
return
self.downloadPic(imglist,picpath)
except Exception as e:
print(e)
time.sleep(3)
prpare函数实现了请求指定网页,并用BeautifulSoup处理回包的功能。
@thread_run
def download(self, url, path):
try:
if lock.acquire():
self.name += 1
imgname = str(self.name)+'.'+url.split('.')[-1]
filename = os.path.join(path,imgname)
lock.release()
print(url)
print(filename)
# res = requests.get(url, headers=header )
res = requests.get(url, headers=HEADERS,timeout=10 )
with open(filename, 'wb') as f:
f.write(res.content)
# 下载完后检查是否完成下载
if lock.acquire():
if self.flag:
self.flag = False
messagebox.showinfo("提示", "下载完成")
lock.release()
except Exception as e:
print(e)
download传给了我们之前封装的装饰器thread_fun, download实现了下载指定图片的功能。
效果展示
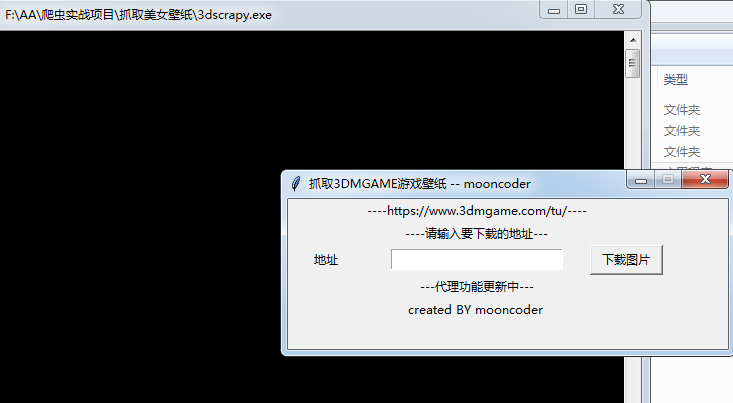 下载图片
下载图片
 感谢关注我的公众号
感谢关注我的公众号
