




分析ajax请求格式,模拟发送http请求,从而获取网页代码,进而分析取出需要的数据和图片。这里分析ajax请求,获取cosplay美女图片。
登陆今日头条,点击搜索,输入cosplay
 下面查看浏览器F12,点击XHR,这里能截取ajax请求,由于已经请求过该页面,所以点击F5,刷新,如下图
下面查看浏览器F12,点击XHR,这里能截取ajax请求,由于已经请求过该页面,所以点击F5,刷新,如下图
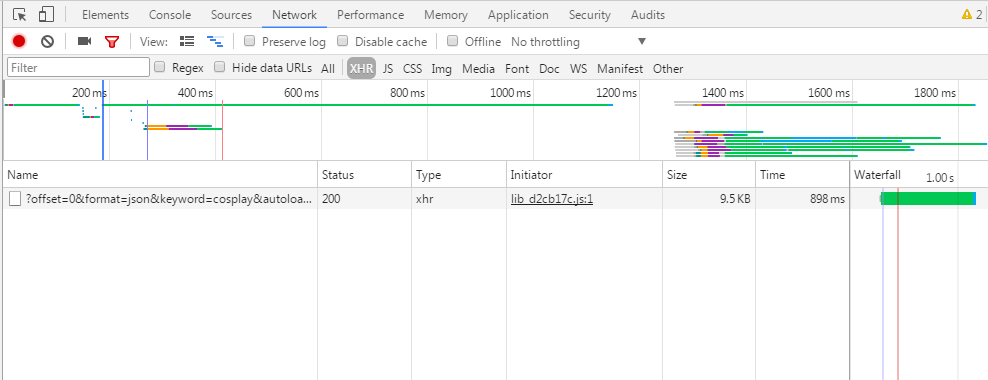 下面我们点击name下的链接,查看headers看到请求信息
下面我们点击name下的链接,查看headers看到请求信息
 可以看到请求的url为
https://www.toutiao.com/search_content/?offset=0&format=json&keyword=cosplay&autoload=true&count=20&cur_tab=1&from=search_tab&pd=synthesis
offset为0,表示当前页面的偏移量,我试着向下滑动页面,name下加载出很多连接,offset每次递增20,keyword为cosplay,是我们搜索的关键词,count表示图集的数量,其他的都不变。
所以我们可以构造一个http请求,包含上面的格式。接下来看看preview的内容
可以看到请求的url为
https://www.toutiao.com/search_content/?offset=0&format=json&keyword=cosplay&autoload=true&count=20&cur_tab=1&from=search_tab&pd=synthesis
offset为0,表示当前页面的偏移量,我试着向下滑动页面,name下加载出很多连接,offset每次递增20,keyword为cosplay,是我们搜索的关键词,count表示图集的数量,其他的都不变。
所以我们可以构造一个http请求,包含上面的格式。接下来看看preview的内容
 data就是页面加载出来的图片文章列表
点击其中一个data,查看
data就是页面加载出来的图片文章列表
点击其中一个data,查看
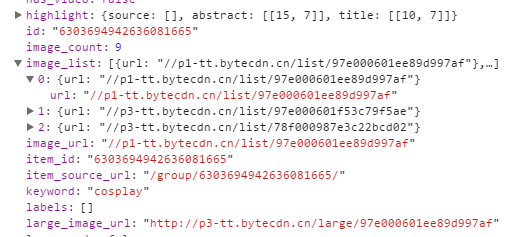 可以看得出图片列表和large图片相差的就是list和large的区别,如
"http://p1-tt.bytecdn.cn/list/97e000601ee89d997af"为缩略图
"http://p1-tt.bytecdn.cn/large/97e000601ee89d997af"为大图
所以只需将list替换为larg即可。之后发送http请求,获取对应的图片即可。下面为完整代码
可以看得出图片列表和large图片相差的就是list和large的区别,如
"http://p1-tt.bytecdn.cn/list/97e000601ee89d997af"为缩略图
"http://p1-tt.bytecdn.cn/large/97e000601ee89d997af"为大图
所以只需将list替换为larg即可。之后发送http请求,获取对应的图片即可。下面为完整代码
import requests
import re
import time
from pyquery import PyQuery as pq
from urllib.parse import urlencode
import os
USER_AGENT = 'Mozilla/5.0 (Windows NT 6.1; WOW64) AppleWebKit/537.36 (KHTML, like Gecko) Chrome/49.0.2623.221 Safari/537.36 SE 2.X MetaSr 1.0'
COOKIES = r'UM_distinctid=167005cc741184-02d14e2fd49b05-10724c6f-1fa400-167005cc74263a; uuid="w:5a4841d5dda248c389f83e5b9c57608a"; sso_uid_tt=45b83f6c549dabd4248c611aa98222d3; toutiao_sso_user=4853db5c812f7bcb367cdcbef0967d06; sso_login_status=1; login_flag=54c7da4daac99058f7b6e4b8975cca01; sessionid=5e86f286970804ed8fd11abf0bf328e4; uid_tt=dd5e177a1cbf9746eb634307d64afd22; sid_tt=5e86f286970804ed8fd11abf0bf328e4; sid_guard="5e86f286970804ed8fd11abf0bf328e4|1541899310|15552000|Fri\054 10-May-2019 01:21:50 GMT"; tt_webid=6622406673465067021; WEATHER_CITY=%E5%8C%97%E4%BA%AC; cp=5BE7386A29798E1; tt_webid=75478811657; __tasessionId=qwly22e8r1541906736076; CNZZDATA1259612802=1520919144-1541896080-https%253A%252F%252Fwww.baidu.com%252F%7C1541901480; csrftoken=b970f054ea259eb162e572217e6756ca'
REFER = 'https://www.toutiao.com/search/?keyword=cosplay'
class AjaxScrapy(object):
def __init__(self,pages=1):
try:
self.m_session = requests.Session()
self.m_headers = {'User-Agent':USER_AGENT,
'referer':REFER,
}
self.m_cookiejar = requests.cookies.RequestsCookieJar()
self.dirpath = os.path.split(os.path.abspath(__file__))[0]
for cookie in COOKIES.split(';'):
key,value = cookie.split('=',1)
self.m_cookiejar.set(key,value)
except:
print('init error!!!')
def getOffset(self,index=0):
try:
params = {
'offset':str(20*index),
'format':'json',
'keyword':'cosplay',
'autoload':'true',
'count':'20',
'cur_tab':'3',
'from':'gallery',
}
httpaddr = 'https://www.toutiao.com/search_content/?'+urlencode(params)
req = self.m_session.get(httpaddr,headers=self.m_headers, cookies=self.m_cookiejar, timeout=5)
if req.status_code != 200:
return None
res = req.json()
if('data' not in res.keys()):
return None
for item in res.get('data'):
if('title' not in item.keys()):
continue
if('image_list' not in item.keys()):
continue
titlenamelist=item['title'].split('/')
titlename = titlenamelist[-1]
savedir=os.path.join(self.dirpath,titlename)
print('正在抓取'+titlename+'.........')
if(os.path.exists(savedir) == False):
os.makedirs(savedir)
imagelist = item.get('image_list')
for imag in imagelist:
if 'url' not in imag.keys():
continue
#print(imag['url'])
image1,image2=imag['url'].split('list')
image3=imag['url'].split('/')[-1]
imagepath=os.path.join(savedir,image3+'.jpg')
if(os.path.exists(imagepath)):
continue
imageaddr = 'http:'+image1+'large'+image2
imagedata=self.m_session.get(imageaddr,timeout=5)
with open (imagepath,'wb')as f:
f.write(imagedata.content)
print('抓取'+titlename+'成功!!!.........')
time.sleep(1)
return req.json()
except:
print('get over view error')
return None
if __name__ == "__main__":
try:
asscrapy = AjaxScrapy()
for i in range(0,5):
res = asscrapy.getOffset(i)
if(res == None):
continue
#print(type(res))
except:
print('scrapy exception!')
pass
更多源码下载;
https://github.com/secondtonone1/python-/tree/master/pythoncookie
个人博客
https://www.limerence2017.com
谢谢关注我的公总号:
