




简介
前文我们通过锁的互斥机制实现了并发安全的栈,队列,查找表,以及链表等结构。接下来本文介绍通过无锁的原子变量的方式实现对应的容器,我们这一篇先从无锁的方式实现栈讲起。
栈的设计思路
栈容器是一种先进后出的结构,简单来讲,我们将n个元素1,2,3,4依次入栈,那么出栈的顺序是4,3,2,1.
先考虑单线程情况下操作顺序
1 创建新节点
2 将元素入栈,将新节点的next指针指向现在的head节点。
3 将head节点更新为新节点的值。
再考虑多线程的情况下
假设线程1执行到第2步,没来得及更新head节点的值为新节点的值。此时线程2也执行完第2步,将head更新为线程2插入的新节点,之后线程1又将head更新为线程1的新插入节点,那么此时head的位置就是错的。
如下图
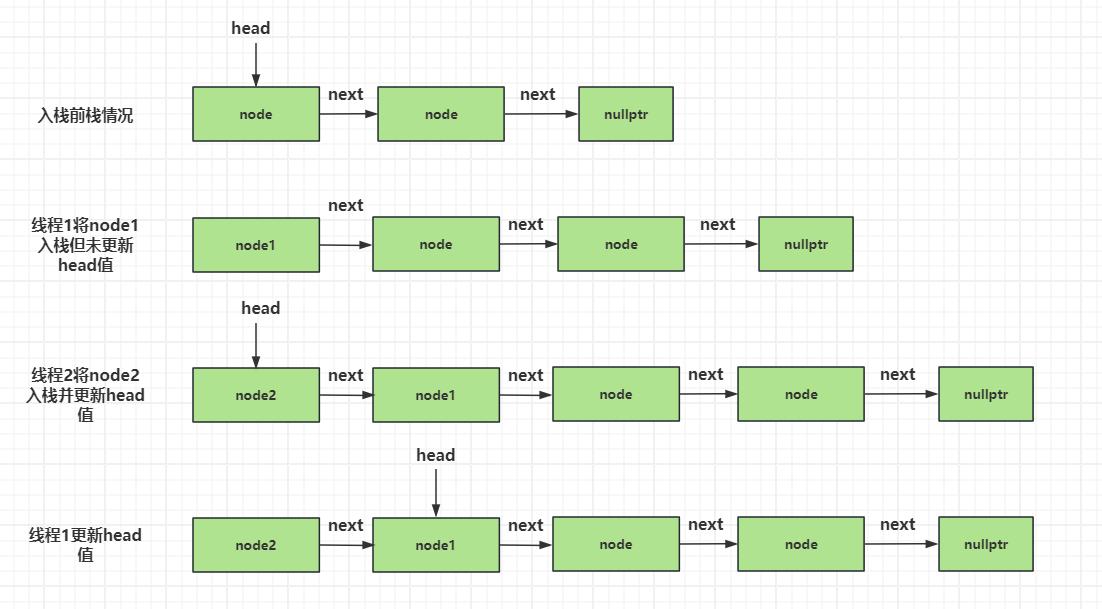
我们可以通过原子变量的compare_exchange(比较交换操作)来控制更新head节点,以此来达到线程安全的目的。
我们先定义节点的结构
template<typename T>
struct node
{
T data;
node* next;
node(T const& data_) :
data(data_)
{}
};
一个node节点包含两部分内容,一个T类型的数据域,一个node*的next指针,指向下一个节点。
我们接下来定义一个无锁栈的结构
template<typename T>
class lock_free_stack
{
private:
lock_free_stack(const lock_free_stack&) = delete;
lock_free_stack& operator = (const lock_free_stack&) = delete;
std::atomic<node*> head;
public:
lock_free_stack() {}
}
我们同样将拷贝构造和拷贝赋值删除了,将head设置为原子变量,这样我们实现push操作的时候,可以通过比较交换的方式达到安全更新head的效果。
template<typename T>
void push(const T& value){
auto new_node = new Node(value)
do{
new_node->next = head.load();
}while(!head.compare_exchange_strong(new_node->next, new_node));
}
当然
template<typename T>
void push(const T& value){
auto new_node = new Node(value)
do{
new_node->next = head.load();
}while(!head.compare_exchange_weak(new_node->next, new_node));
}
我还是建议大家用do-while的方式实现,这样我们可以在do-while中增加很多自己的定制逻辑,另外推荐大家用compare_exchange_weak,尽管存在失败的情况,但是他的开销小,所以compare_exchange_weak返回false我们再次重试即可。
单线程情况下pop操作的顺序
1 取出头节点元素
2 更新head为下一个节点。
3 返回取出头节点元素的数据域。
多线程情况下,第1,2点同样存在线程安全问题。此外我们返回节点数据域时会进行拷贝赋值,如果出现异常会造成数据丢失,这一点也要考虑。 所以我们同样通过head原子变量比较和交换的方式检测并取出头部节点。
我们先写一个单线程版本
template<typename T>
void pop(T& value){
node* old_head = head.load(); //1
head = head->next; //2
value = old_head->data;
}
我们知道1处和2处在多线程情况下会存在线程安全问题。所以我们用原子变量的比较交换操作改写上面的代码
template<typename T>
void pop(T& value){
do{
node* old_head = head.load(); //1
}while(!head.compare_exchange_weak(old_head, old_head->next)); //2
value = old_head->data; //3
}
我们通过判断head和old_head的值是否相等,如果相等则将head的值设置为old_head的下一个节点,否则返回false,并且将old_head更新为当前head的值(比较交换函数帮我们做的)。
我们看上面的代码,有三点严重问题
1 未判断空栈的情况,这一点比较好处理,如果为空栈我们可以令pop返回false,或者抛出异常,当然抛出异常不可取。
2 将数据域赋值给引用类型的value时存在拷贝赋值(3处),我们都知道拷贝赋值会存在异常的情况,当异常发生时元素已经从栈定移除了,破坏了栈的结构,这一点和锁处理时不一样,锁处理的时候是先将元素数据域取出赋值再出栈,所以不会有问题,但是无锁的方式就会出现栈被破坏的情况。解决方式也比较简单,数据域不再存储T类型数据,而是存储std::shared_ptr<T>类型的数据。智能指针在赋值的时候不会产生异常。
3 未释放弹出的节点的内存。
那我们修改之后的代码就是这样了
class lock_free_stack
{
private:
struct node
{
std::shared_ptr<T> data;
node* next;
node(T const& data_) : //⇽-- - 1
data(std::make_shared<T>(data_))
{}
};
lock_free_stack(const lock_free_stack&) = delete;
lock_free_stack& operator = (const lock_free_stack&) = delete;
std::atomic<node*> head;
public:
lock_free_stack() {}
void push(T const& data)
{
node* const new_node = new node(data); //⇽-- - 2
new_node->next = head.load(); //⇽-- - 3
while (!head.compare_exchange_weak(new_node->next, new_node)); //⇽-- - 4
}
std::shared_ptr<T> pop() {
node* old_head = nullptr; //1
do {
old_head = head.load(); //2
if (old_head == nullptr) {
return nullptr;
}
} while (!head.compare_exchange_weak(old_head, old_head->next)); //3
return old_head->data; //4
}
};
简单描述下pop函数的功能,
1 处初始化一个临时old_head的变量,
2 处加载head节点
3 处通过比较和交换操作,判断head和old_head是否相等,如相等则将head更新为old_head的next节点。如不相等,将old_head更新为head的值(compare_exchange_weak自动帮我们做了),再次进入循环。尽管2处又加载了一次head的值给old_head有些重复,但是为了代码的可读性和指针判空,我觉得这么写更合适一点。
资源回收的问题我们还没处理。 我们先实现一个简单的回收处理逻辑
template<typename T>
std::shared_ptr<T> pop() {
node* old_head = nullptr; //1
do {
old_head = head.load();
if (old_head == nullptr) {
return nullptr;
}
} while (!head.compare_exchange_weak(old_head, old_head->next)); //2
std::shared_ptr<T> res; //3
res.swap(old_head->data); //4
delete old_head; //5
return res; //6
}
上面的代码在3处定义了一个T类型的智能指针res用来返回pop的结果,所以在4处将old_head的data值转移给res,这样就相当于清除old_head的data了。
在5处删除了old_head. 意在回收数据,但这存在很大问题,比如线程1执行到5处删除old_head,而线程2刚好执行到2处用到了和线程1相同的old_head,线程2执行compare_exchange_weak的时候old_head->next会引发崩溃。
所以要引入一个机制,延迟删除节点。将本该及时删除的节点放入待珊节点。基本思路如下
1 如果有多个线程同时pop,而且存在一个线程1已经交换取出head数据并更新了head值,另一个线程2即将基于旧有的head获取next数据,如果线程1删除了旧有head,线程2就有可能产生崩溃。这种情况我们就要将线程1取出的head放入待删除的列表。
2 同一时刻仅有一个线程1执行pop函数,不存在其他线程。那么线程1可以将旧head删除,并删除待删列表中的其他节点。
3 如果线程1已经将head节点交换弹出,线程2还未执行pop操作,当线程1准备将head删除时发现此时线程2进入执行pop操作,那么线程1能将旧head删除,因为线程2读取的head和线程1不同(线程2读取的是线程1交换后新的head值)。此情形和情形1略有不同,情形1是两个线程同时pop只有一个线程交换成功的情况,情形3是一个线程已经将head交换出,准备删除之前发现线程2执行pop进入,所以这种情况下线程1可将head删除,但是线程1不能将待删除列表删除,因为有其他线程可能会用到待删除列表中的节点。
我们思考这种情形
线程1 执行pop已经将head换出
线程2 执行pop函数,发现线程1正在pop操作,线程2就将待删除的节点head(此head非线程1head)放入待删列表.
线程3 和线程2几乎同时执行pop函数但是还未执行head的交换操作,此head和线程2的head相同。
这种情况下线程1可能读取待删列表为空,因为线程2可能还未更新,也可能读取待删列表不为空(线程2已更新),但是线程1不能删除这个待删列表,因为线程3可能在用。
那基于上述三点,我们可以简单理解为
1 如果head已经被更新,且旧head不会被其他线程引用,那旧head就可以被删除。否则放入待删列表。
2 如果仅有一个线程执行pop操作,那么待删列表可以被删除,如果有多个线程执行pop操作,那么待删列表不可被删除。
我们需要用一个原子变量threads_in_pop记录有几个线程执行pop操作。在pop结束后再减少threads_in_pop。 我们需要一个原子变量to_be_deleted记录待删列表的首节点。
那么我们先实现一个改造版本
std::shared_ptr<T> pop() {
//1 计数器首先自增,然后才执行其他操作
++threads_in_pop;
node* old_head = nullptr;
do {
//2 加载head节点给旧head存储
old_head = head.load();
if (old_head == nullptr) {
--threads_in_pop;
return nullptr;
}
} while (!head.compare_exchange_weak(old_head, old_head->next)); // 3
//3处 比较更新head为旧head的下一个节点
std::shared_ptr<T> res;
if (old_head)
{
// 4 只要有可能,就回收已删除的节点数据
res.swap(old_head->data);
}
// 5 从节点提取数据,而非复制指针
try_reclaim(old_head);
return res;
}
1 在1处我们对原子变量threads_in_pop增加以表示线程执行pop函数。
2 在2处我们将head数据load给old_head。如果old_head为空则直接返回。
3 3处通过head和old_head作比较,如果相等则交换,否则重新do while循环。这么做的目的是为了防止多线程访问,保证只有一个线程将head更新为old_head的下一个节点。
4 将old_head的数据data交换给res。
5 try_reclaim函数就是删除old_head或者将其放入待删列表,以及判断是否删除待删列表。
接下来我们实现try_reclaim函数
void try_reclaim(node* old_head)
{
//1 原子变量判断仅有一个线程进入
if(threads_in_pop == 1)
{
//2 当前线程把待删列表取出
node* nodes_to_delete = to_be_deleted.exchange(nullptr);
//3 更新原子变量获取准确状态,判断pop是否仅仅正被当前线程唯一调用
if(!--threads_in_pop)
{
//4 如果唯一调用则将待删列表删除
delete_nodes(nodes_to_delete);
}else if(nodes_to_delete)
{
//5 如果pop还有其他线程调用且待删列表不为空,
//则将待删列表首节点更新给to_be_deleted
chain_pending_nodes(nodes_to_delete);
}
delete old_head;
}
else {
//多个线程pop竞争head节点,此时不能删除old_head
//将其放入待删列表
chain_pending_node(old_head);
--threads_in_pop;
}
}
1 1处我们判断pop的线程数是否为1,并没有采用load,也就是即便判断的时候其他线程也可以pop,这样不影响效率,即便模糊判断threads_in_pop为1,同一时刻threads_in_pop可能会增加也没关系,threads_in_pop为1仅表示当前时刻走入1处逻辑之前仅有该线程执行pop,那说明没有其他线程竞争head,head已经被更新为新的值,其他线程之后pop读取的head和我们要删除的old_head不是同一个,就是可以被直接删除的。
2 处我们将当前待删除的列表交换给本线程的nodes_to_delete临时变量,表示接管待删除列表。但是能否删除还要判断是不是仅有本线程在执行pop。
3 处更新原子变量获取准确状态,判断pop是否仅仅正被当前线程唯一调用,如果是被唯一调用则删除待删列表,否则将nodes_to_delete临时变量再更新回待删列表。(因为可能有多个线程会用待删列表中的节点)
接下来我们实现delete_nodes函数, 该函数用来删除以nodes为首节点的链表,该函数写成了static函数,也可以用普通函数。
static void delete_nodes(node* nodes)
{
while (nodes)
{
node* next = nodes->next;
delete nodes;
nodes = next;
}
}
接下来实现chain_pending_node函数,该函数用来将单个节点放入待删列表
void chain_pending_node(node* n)
{
chain_pending_nodes(n, n);
}
chain_pending_nodes接受两个参数,分别为链表的头和尾。
void chain_pending_nodes(node* first, node* last)
{
//1 先将last的next节点更新为待删列表的首节点
last->next = to_be_deleted;
//2 借循环保证 last->next指向正确
// 将待删列表的首节点更新为first节点
while (!to_be_deleted.compare_exchange_weak(
last->next, first));
}
1 处将last->next的值更新为to_be_deleted, 这么做的一个好处是如果有其他线程修改了to_be_deleted.能保证当前线程的last->next指向的是最后修改的to_be_deleted,达到链接待删列表的作用。
2 处可能更新失败,因为其他线程修改了to_be_deleted的值,但是不要紧,我们再次循环直到匹配last->next的值为to_be_deleted为止,将to_be_deleted更新为first的值。
接下来我们还要实现将nodes_to_delete为首的链表还原到待删列表中, 函数为chain_pending_nodes接受一个参数为待还原的链表的首节点
void chain_pending_nodes(node* nodes)
{
node* last = nodes;
//1 沿着next指针前进到链表末端
while (node* const next = last->next)
{
last = next;
}
//2 将链表放入待删链表中
chain_pending_nodes(nodes, last);
}
分析
上面的无锁栈存在一个问题,就是当多个线程pop时将要删除的节点放入待删列表中,如果每次pop都会被多个线程调用,则要删除的节点就会一直往待删除列表中增加,导致待删除列表无法被回收。这个问题我们可以考虑当pop执行结束时最后一个线程回收待删列表。留作下一节分析。
我们先写一个函数测试以下
void TestLockFreeStack() {
lock_free_stack<int> lk_free_stack;
std::set<int> rmv_set;
std::mutex set_mtx;
std::thread t1([&]() {
for (int i = 0; i < 20000; i++) {
lk_free_stack.push(i);
std::cout << "push data " << i << " success!" << std::endl;
}
});
std::thread t2([&]() {
for (int i = 0; i < 10000;) {
auto head = lk_free_stack.pop();
if (!head) {
std::this_thread::sleep_for(std::chrono::milliseconds(10));
continue;
}
std::lock_guard<std::mutex> lock(set_mtx);
rmv_set.insert(*head);
std::cout << "pop data " << *head << " success!" << std::endl;
i++;
}
});
std::thread t3([&]() {
for (int i = 0; i < 10000;) {
auto head = lk_free_stack.pop();
if (!head) {
std::this_thread::sleep_for(std::chrono::milliseconds(10));
continue;
}
std::lock_guard<std::mutex> lock(set_mtx);
rmv_set.insert(*head);
std::cout << "pop data " << *head << " success!" << std::endl;
i++;
}
});
t1.join();
t2.join();
t3.join();
assert(rmv_set.size() == 20000);
}
1 线程t1将0到20000个数放入集合中。 2 线程t2和t3分别出栈10000次。 3 最后我们断言集合的大小为20000.
测试结果如下
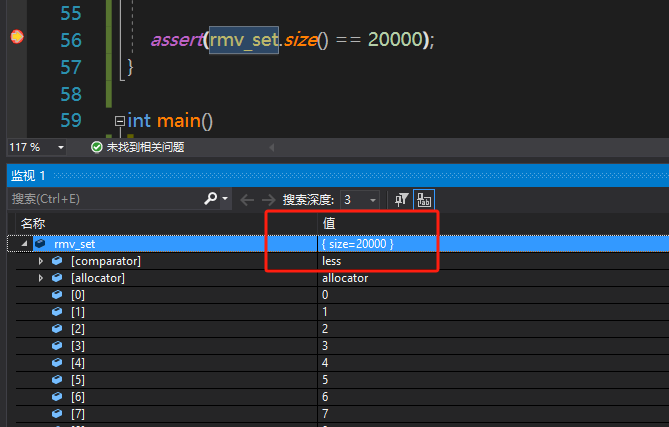
可以看到我们的集合大小为20000,且数据唯一。
总结
源码链接:
https://gitee.com/secondtonone1/boostasio-learn/tree/master/concurrent/day17-LockFreeStack
视频链接
https://space.bilibili.com/271469206/channel/collectiondetail?sid=1623290