




前几篇文章介绍了urllib库基本使用和爬虫的简单应用,本文介绍如何通过post信息给网站,保存登陆后cookie,并用于请求有
权限的操作。保存cookie需要用到cookiejar类,可以输出cookie信息查看下
import http.cookiejar
import urllib.request
#声明一个CookieJar对象实例来保存cookie
cookie = http.cookiejar.CookieJar()
#HTTPCookieProcessor对象来创建cookie处理器
handler = urllib.request.HTTPCookieProcessor(cookie)
#通过handler来构建opener
opener = urllib.request.build_opner(handler)
#通过opner访问网址
response = opner.open('http://www.baidu.com')
#访问cookie中的数据
for item in cookie:
print('Name = '+ item.name)
print('Value = '+ item.value)
1 通过http.cookiejar.CookieJar()创建一个cookiejar对象,用来保存上网留下的cookie。 2 为了处理cookie,需要创建cookie处理器,通过urllib.request.HTTPCookieProcessor(cookie)根据cookie 创建cookie处理器。 3 接下来根据cookie处理器,建立opener, urllib.request.build_opener(handler)创建opener 4 通过openr访问cookie中的数据
可以保存cookie,用于以后访问有权限的网页。下面将cookie写入文件
#定义文件名
filename = 'cookie.txt'
#定义MozillaCookieJar对象保存cookie,并且cookie关联上filename文件
cookie = http.cookiejar.MozillaCookieJar(filename)
#创建cookie处理器
handler = request.HTTPCookieProcessor(cookie)
#通过handler构建opener
opener = request.build_opener(handler)
#利用opener请求网页
response = opener.open('http://www.baidu.com')
#保存cookie到文件
cookie.save(ignore_discard = True, ignore_expires = True)
1 传入文件名,调用http.cookiejar.MozillaCookieJar创建cookie, cookie和文件名绑定了。 2 根据cookie创建处理器, request.HTTPCookieProcessor创建handler 3 根据Cookie处理器创建opener 4 用opener访问网站,生成cookie 5 cookie.save保存到filename文件中,ignore_discard表示忽略是否过期, 及时被丢弃也保存。ignore_expires表示文件存在则覆盖写入。
对于保存好的cookie文件,可以提取并访问其他网页。
filename = 'cookie.txt'
#创建MozillaCookieJar对象
cookie = http.cookiejar.MozillaCookieJar()
#从文件中读取cookie内容到变量
cookie.load(filename, ignore_discard = True, ignore_expires = True)
#生成cookie处理器
handler = request.HTTPCookieProcessor(cookie)
#创建opener
opener = request.build_opener(handler)
#用opener打开网页
response = opener.open('http://www.baidu.com')
print(response.read().decode('utf-8'))
1 用MozillaCookieJar创建cookie 2 调用cookie.load加载文件内容到cookie中 3 根据cookie创建HTTPCookieProcessor 4 根据handler创建opener 5 利用opener打开网页,返回response
下面综合应用上面的知识,用爬虫模拟登陆,然后获取有权限的网页和信息。
通过浏览器审查元素的方式可以查看访问网站的request和response,用fiddler更方便一些,用fidder监控浏览器
数据,然后模拟浏览器发送登录请求。
随便找一个需要登陆的网站
http://www.lesmao.cc/forum.php
找到登陆按钮,点击登陆,查看fiddler监控的数据。
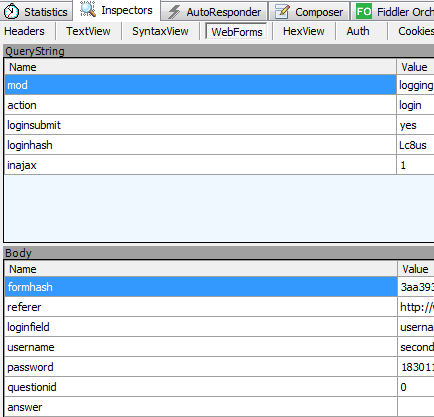
可以在fiddler中看到这个request请求post数据给网站。
 通过webform这一选项看到我们投递的消息
通过webform这一选项看到我们投递的消息
 有些网页是需要登陆才能访问的,如
http://www.lesmao.cc/home.php?mod=space&do=notice&view=system
有些网页是需要登陆才能访问的,如
http://www.lesmao.cc/home.php?mod=space&do=notice&view=system
下面先模拟登陆,获取cookie,然后利用cookie访问个人信息网页。
if __name__ == '__main__':
#登陆地址
login_url = 'http://www.lesmao.cc/member.php?mod=logging&action=login&referer='
#User-Agent信息
user_agent = r'Mozilla/5.0 (Windows NT 6.1; WOW64) AppleWebKit/537.36 (KHTML, like Gecko) Chrome/49.0.2623.221 Safari/537.36 SE 2.X MetaSr 1.0'
#Headers信息
head = {'User-Agnet': user_agent, 'Connection': 'keep-alive'}
#登陆Form_Data信息
Login_Data = {}
Login_Data['formhash'] = '5ea0f6e4'
Login_Data['referer'] = 'http://www.lesmao.cc/./'
Login_Data['loginfield'] = 'username'
Login_Data['username'] = 'secondtonone1'
Login_Data['password'] = '18301152001'
Login_Data['loginsubmit'] = 'true'
Login_Data['questionid'] = '0'
Login_Data['answer'] = ''
#使用urlencode方法转换标准格式
logingpostdata = parse.urlencode(Login_Data).encode('utf-8')
#声明一个CookieJar对象实例来保存cookie
cookie = cookiejar.CookieJar()
#利用urllib.request库的HTTPCookieProcessor对象来创建cookie处理器,也就CookieHandler
cookie_support = request.HTTPCookieProcessor(cookie)
#通过CookieHandler创建opener
opener = request.build_opener(cookie_support)
#创建Request对象
req1 = request.Request(url=login_url, data=logingpostdata, headers=head)
#面向对象地址
date_url = 'http://www.lesmao.cc/home.php?mod=space&do=notice&view=system'
req2 = request.Request(url=date_url, headers=head)
try:
#使用自己创建的opener的open方法
response1 = opener.open(req1)
#print(response1.read().decode('utf-8'))
print('.................................')
response2 = opener.open(req2)
html = response2.read().decode('utf-8')
#打印查询结果
print(html)
except error.URLError as e:
if hasattr(e, 'code'):
print("URLError:%d" % e.code)
if hasattr(e, 'reason'):
print("URLError:%s" % e.reason)
except error.HTTPError as e:
if hasattr(e, 'code'):
print("URLError:%d" % e.code)
if hasattr(e, 'reason'):
print("URLError:%s" % e.reason)
except Exception as e:
print('Exception is : ', e)
打印出的html信息和登陆后点击的信息是一致的,所以用cookie登陆并访问其它权限网页成功了。
源码下载地址:
源码下载
我的公众号:
