




简介
C++的标准模板库(STL)提供了多种通用容器,用于存储和管理数据。这些容器各有特点,适用于不同的应用场景。理解每种容器的用法和内部实现原理,对于编写高效且可维护的代码至关重要。本教案将详细介绍几种常用的STL容器,包括vector、list、deque、map、unordered_map、set、unordered_set以及容器适配器如stack、queue和priority_queue。
vector:动态数组
用法
vector是STL中最常用的序列容器之一,提供了动态大小的数组功能。它支持随机访问,允许在末尾高效地添加和删除元素。
内部实现原理
vector在内部使用动态数组(通常是连续的内存块)来存储元素。当需要扩展容量时,它会分配一块更大的内存,将现有元素复制到新内存中,然后释放旧内存。这种策略在平均情况下保证了push_back的常数时间复杂度。
性能特性
- 随机访问:支持常数时间的随机访问(
O(1))。 - 末尾插入/删除:
push_back和pop_back操作在摊销分析下是常数时间(O(1))。 - 中间插入/删除:在中间位置插入或删除元素需要移动后续元素,时间复杂度为线性时间(
O(n))。
应用场景
- 需要频繁随机访问元素。
- 主要在容器末尾进行插入和删除操作。
- 当容器大小不需要频繁调整(避免频繁的内存重新分配)。
代码示例
#include <iostream>
#include <vector>
int main() {
// 创建一个空的整数vector
std::vector<int> numbers;
// 向vector末尾添加元素
numbers.push_back(10);
numbers.push_back(20);
numbers.push_back(30);
// 通过索引访问元素
std::cout << "第一个元素: " << numbers[0] << std::endl;
// 遍历vector
std::cout << "所有元素: ";
for(auto it = numbers.begin(); it != numbers.end(); ++it) {
std::cout << *it << " ";
}
std::cout << std::endl;
// 删除最后一个元素
numbers.pop_back();
// 打印删除后的vector
std::cout << "删除最后一个元素后: ";
for(auto num : numbers) {
std::cout << num << " ";
}
std::cout << std::endl;
return 0;
}
输出
第一个元素: 10
所有元素: 10 20 30
删除最后一个元素后: 10 20
list:双向链表
用法
list是一个实现了双向链表的数据结构,适合在容器中间频繁插入和删除元素。与vector不同,list不支持随机访问,但在任何位置的插入和删除操作都是常数时间。
内部实现原理
list在内部使用双向链表,每个元素包含指向前一个和后一个元素的指针。这使得在已知位置插入或删除元素时,无需移动其他元素,只需更新指针即可。
性能特性
- 随机访问:不支持随机访问,访问第
n个元素需要线性时间(O(n))。 - 中间插入/删除:已知位置的插入和删除操作是常数时间(
O(1))。 - 遍历:顺序遍历,适合需要频繁遍历但不需要随机访问的场景。
应用场景
- 需要在容器中间频繁插入或删除元素。
- 不需要进行随机访问。
- 对内存的局部性要求不高(链表元素在内存中不连续)。
代码示例
#include <iostream>
#include <list>
int main() {
// 创建一个空的整数list
std::list<int> numbers;
// 向list末尾添加元素
numbers.push_back(100);
numbers.push_back(200);
numbers.push_back(300);
// 向list前端添加元素
numbers.push_front(50);
// 遍历list
std::cout << "所有元素: ";
for(auto it = numbers.begin(); it != numbers.end(); ++it) {
std::cout << *it << " ";
}
std::cout << std::endl;
// 插入元素
auto it = numbers.begin();
++it; // 指向第二个元素
numbers.insert(it, 150);
// 打印插入后的list
std::cout << "插入元素后: ";
for(auto num : numbers) {
std::cout << num << " ";
}
std::cout << std::endl;
// 删除元素
numbers.remove(200);
// 打印删除后的list
std::cout << "删除元素后: ";
for(auto num : numbers) {
std::cout << num << " ";
}
std::cout << std::endl;
return 0;
}
输出
所有元素: 50 100 200 300
插入元素后: 50 150 100 200 300
删除元素后: 50 150 100 300
模拟实现一个简化版的 List
为了更好地理解 std::list 的内部工作原理,我们可以尝试模拟实现一个简化版的双向链表。下面将逐步介绍如何设计和实现这个 List 类。
类设计
我们的 List 类将包含以下组件:
- 节点结构体(Node):表示链表的每个节点。
- 迭代器类(Iterator):允许用户遍历链表。
List类:管理链表的基本操作,如插入、删除和遍历。
节点结构体
每个节点包含数据域和前后指针:
template<typename T>
struct Node {
T data;
Node* prev;
Node* next;
Node(const T& value = T()) : data(value), prev(nullptr), next(nullptr) {}
};
迭代器实现
为了实现双向迭代器,我们需要定义一个 Iterator 类,支持 ++ 和 -- 操作。
template<typename T>
class List;
template<typename T>
class Iterator {
public:
using self_type = Iterator<T>;
using value_type = T;
using reference = T&;
using pointer = T*;
using iterator_category = std::bidirectional_iterator_tag;
using difference_type = std::ptrdiff_t;
Iterator(Node<T>* ptr = nullptr) : node_ptr(ptr) {}
// Dereference operator
reference operator*() const { return node_ptr->data; }
// Arrow operator
pointer operator->() const { return &(node_ptr->data); }
// Pre-increment
self_type& operator++() {
if (node_ptr) node_ptr = node_ptr->next;
return *this;
}
// Post-increment
self_type operator++(int) {
self_type temp = *this;
++(*this);
return temp;
}
// Pre-decrement
self_type& operator--() {
if (node_ptr) node_ptr = node_ptr->prev;
return *this;
}
// Post-decrement
self_type operator--(int) {
self_type temp = *this;
--(*this);
return temp;
}
// Equality comparison
bool operator==(const self_type& other) const {
return node_ptr == other.node_ptr;
}
// Inequality comparison
bool operator!=(const self_type& other) const {
return node_ptr != other.node_ptr;
}
private:
Node<T>* node_ptr;
friend class List<T>;
};
List 类
List 类提供链表的基本功能。
#include <iostream>
template<typename T>
class List {
public:
using iterator = Iterator<T>;
using const_iterator = Iterator<T>;
// 构造函数
List() {
head = new Node<T>(); // 哨兵节点
tail = new Node<T>(); // 哨兵节点
head->next = tail;
tail->prev = head;
}
// 析构函数
~List() {
clear();
delete head;
delete tail;
}
// 禁止拷贝构造和赋值操作(简化实现)
List(const List& other) = delete;
List& operator=(const List& other) = delete;
// 插入元素到迭代器位置之前
iterator insert(iterator pos, const T& value) {
Node<T>* current = pos.node_ptr;
Node<T>* new_node = new Node<T>(value);
Node<T>* prev_node = current->prev;
new_node->next = current;
new_node->prev = prev_node;
prev_node->next = new_node;
current->prev = new_node;
return iterator(new_node);
}
// 删除迭代器指向的元素
iterator erase(iterator pos) {
Node<T>* current = pos.node_ptr;
if (current == head || current == tail) {
// 不能删除哨兵节点
return pos;
}
Node<T>* prev_node = current->prev;
Node<T>* next_node = current->next;
prev_node->next = next_node;
next_node->prev = prev_node;
delete current;
return iterator(next_node);
}
// 在头部插入元素
void push_front(const T& value) {
insert(begin(), value);
}
// 在尾部插入元素
void push_back(const T& value) {
insert(end(), value);
}
// 在头部删除元素
void pop_front() {
if (!empty()) {
erase(begin());
}
}
// 在尾部删除元素
void pop_back() {
if (!empty()) {
iterator temp = end();
--temp;
erase(temp);
}
}
// 获取头元素引用
T& front() {
return head->next->data;
}
// 获取尾元素引用
T& back() {
return tail->prev->data;
}
// 判断是否为空
bool empty() const {
return head->next == tail;
}
// 获取链表大小(O(n)复杂度)
size_t size() const {
size_t count = 0;
for(auto it = begin(); it != end(); ++it) {
++count;
}
return count;
}
// 清空链表
void clear() {
Node<T>* current = head->next;
while(current != tail) {
Node<T>* temp = current;
current = current->next;
delete temp;
}
head->next = tail;
tail->prev = head;
}
// 获取开始迭代器
iterator begin() {
return iterator(head->next);
}
// 获取结束迭代器
iterator end() {
return iterator(tail);
}
// 打印链表(辅助函数)
void print() const {
Node<T>* current = head->next;
while(current != tail) {
std::cout << current->data << " ";
current = current->next;
}
std::cout << std::endl;
}
private:
Node<T>* head; // 头哨兵
Node<T>* tail; // 尾哨兵
};
完整代码示例
下面是一个完整的示例,包括创建 List 对象,进行各种操作,并打印结果。
#include <iostream>
// 节点结构体
template<typename T>
struct Node {
T data;
Node* prev;
Node* next;
Node(const T& value = T()) : data(value), prev(nullptr), next(nullptr) {}
};
// 迭代器类
template<typename T>
class Iterator {
public:
using self_type = Iterator<T>;
using value_type = T;
using reference = T&;
using pointer = T*;
using iterator_category = std::bidirectional_iterator_tag;
using difference_type = std::ptrdiff_t;
Iterator(Node<T>* ptr = nullptr) : node_ptr(ptr) {}
// Dereference operator
reference operator*() const { return node_ptr->data; }
// Arrow operator
pointer operator->() const { return &(node_ptr->data); }
// Pre-increment
self_type& operator++() {
if (node_ptr) node_ptr = node_ptr->next;
return *this;
}
// Post-increment
self_type operator++(int) {
self_type temp = *this;
++(*this);
return temp;
}
// Pre-decrement
self_type& operator--() {
if (node_ptr) node_ptr = node_ptr->prev;
return *this;
}
// Post-decrement
self_type operator--(int) {
self_type temp = *this;
--(*this);
return temp;
}
// Equality comparison
bool operator==(const self_type& other) const {
return node_ptr == other.node_ptr;
}
// Inequality comparison
bool operator!=(const self_type& other) const {
return node_ptr != other.node_ptr;
}
private:
Node<T>* node_ptr;
friend class List<T>;
};
// List 类
template<typename T>
class List {
public:
using iterator = Iterator<T>;
using const_iterator = Iterator<T>;
// 构造函数
List() {
head = new Node<T>(); // 头哨兵
tail = new Node<T>(); // 尾哨兵
head->next = tail;
tail->prev = head;
}
// 析构函数
~List() {
clear();
delete head;
delete tail;
}
// 禁止拷贝构造和赋值操作(简化实现)
List(const List& other) = delete;
List& operator=(const List& other) = delete;
// 插入元素到迭代器位置之前
iterator insert(iterator pos, const T& value) {
Node<T>* current = pos.node_ptr;
Node<T>* new_node = new Node<T>(value);
Node<T>* prev_node = current->prev;
new_node->next = current;
new_node->prev = prev_node;
prev_node->next = new_node;
current->prev = new_node;
return iterator(new_node);
}
// 删除迭代器指向的元素
iterator erase(iterator pos) {
Node<T>* current = pos.node_ptr;
if (current == head || current == tail) {
// 不能删除哨兵节点
return pos;
}
Node<T>* prev_node = current->prev;
Node<T>* next_node = current->next;
prev_node->next = next_node;
next_node->prev = prev_node;
delete current;
return iterator(next_node);
}
// 在头部插入元素
void push_front(const T& value) {
insert(begin(), value);
}
// 在尾部插入元素
void push_back(const T& value) {
insert(end(), value);
}
// 在头部删除元素
void pop_front() {
if (!empty()) {
erase(begin());
}
}
// 在尾部删除元素
void pop_back() {
if (!empty()) {
iterator temp = end();
--temp;
erase(temp);
}
}
// 获取头元素引用
T& front() {
return head->next->data;
}
// 获取尾元素引用
T& back() {
return tail->prev->data;
}
// 判断是否为空
bool empty() const {
return head->next == tail;
}
// 获取链表大小(O(n)复杂度)
size_t size() const {
size_t count = 0;
for(auto it = begin(); it != end(); ++it) {
++count;
}
return count;
}
// 清空链表
void clear() {
Node<T>* current = head->next;
while(current != tail) {
Node<T>* temp = current;
current = current->next;
delete temp;
}
head->next = tail;
tail->prev = head;
}
// 获取开始迭代器
iterator begin() {
return iterator(head->next);
}
// 获取结束迭代器
iterator end() {
return iterator(tail);
}
// 打印链表(辅助函数)
void print() const {
Node<T>* current = head->next;
while(current != tail) {
std::cout << current->data << " ";
current = current->next;
}
std::cout << std::endl;
}
private:
Node<T>* head; // 头哨兵
Node<T>* tail; // 尾哨兵
};
// 测试代码
int main() {
List<int> lst;
// 插入元素
lst.push_back(10); // 链表: 10
lst.push_front(5); // 链表: 5, 10
lst.push_back(15); // 链表: 5, 10, 15
lst.insert(++lst.begin(), 7); // 链表: 5, 7, 10, 15
// 打印链表
std::cout << "链表内容: ";
lst.print(); // 输出: 5 7 10 15
// 删除元素
lst.pop_front(); // 链表: 7, 10, 15
lst.pop_back(); // 链表: 7, 10
// 打印链表
std::cout << "删除头尾后链表内容: ";
lst.print(); // 输出: 7 10
// 插入和删除
auto it = lst.begin();
lst.insert(it, 3); // 链表: 3, 7, 10
lst.erase(++it); // 链表: 3, 10
// 打印链表
std::cout << "插入和删除后链表内容: ";
lst.print(); // 输出: 3 10
// 清空链表
lst.clear();
std::cout << "清空后,链表是否为空: " << (lst.empty() ? "是" : "否") << std::endl;
return 0;
}
代码解释
节点结构体
Node:包含数据域data,前驱指针prev和后继指针next。迭代器类
Iterator:构造函数:接受一个
Node<T>*指针。重载操作符
:
*和->用于访问节点数据。++和--支持前向和后向遍历。==和!=用于比较迭代器。
List类:成员变量
:
head和tail是头尾哨兵节点。
构造函数:初始化头尾哨兵,并将它们互相连接。
析构函数:清空链表并删除哨兵节点。
insert:在指定位置前插入新节点。erase:删除指定位置的节点。push_front和push_back:分别在头部和尾部插入元素。pop_front和pop_back:分别删除头部和尾部元素。front和back:访问头尾元素。empty和size:检查链表是否为空和获取链表大小。clear:清空链表。begin和end:返回开始和结束迭代器。print:辅助函数,用于打印链表内容。
测试代码:创建
List<int>对象,并执行一系列的插入、删除和遍历操作,验证List类的功能。
编译和运行
保存上述代码到一个名为 List.cpp 的文件中,然后使用以下命令编译和运行:
g++ -std=c++11 -o List List.cpp
./List
输出结果:
链表内容: 5 7 10 15
删除头尾后链表内容: 7 10
插入和删除后链表内容: 3 10
清空后,链表是否为空: 是
迭代器分类
1. 迭代器(Iterator)简介
在 C++ 中,迭代器 是一种用于遍历容器(如 std::vector、std::list 等)元素的对象。它们提供了类似指针的接口,使得算法可以独立于具体的容器而工作。迭代器的设计允许算法以统一的方式处理不同类型的容器。
2. 迭代器类别(Iterator Categories)
为了使不同类型的迭代器能够支持不同的操作,C++ 标准库将迭代器分为以下几种类别,每种类别支持的操作能力逐级增强:
- 输入迭代器(Input Iterator)
- 输出迭代器(Output Iterator)
- 前向迭代器(Forward Iterator)
- 双向迭代器(Bidirectional Iterator)
- 随机访问迭代器(Random Access Iterator)
- 无效迭代器(Contiguous Iterator)(C++20 引入)
每个类别都继承自前一个类别,具备更强的功能。例如,双向迭代器不仅支持前向迭代器的所有操作,还支持反向迭代(即可以向后移动)。
主要迭代器类别及其特性
| 类别 | 支持的操作 | 示例容器 |
|---|---|---|
| 输入迭代器 | 只读访问、单向前进 | 单向链表 std::forward_list |
| 输出迭代器 | 只写访问、单向前进 | 输出流 std::ostream_iterator |
| 前向迭代器 | 读写访问、单向前进 | 向量 std::vector |
| 双向迭代器 | 读写访问、单向前进和反向迭代 | 双向链表 std::list |
| 随机访问迭代器 | 读写访问、单向前进、反向迭代、跳跃移动(支持算术运算) | 向量 std::vector、队列 std::deque |
| 无效迭代器(新) | 随机访问迭代器的所有功能,且元素在内存中连续排列 | 新的 C++ 容器如 std::span |
3. iterator_category 的作用
iterator_category 是迭代器类型中的一个别名,用于标识该迭代器所属的类别。它是标准库中 迭代器特性(Iterator Traits) 的一部分,标准算法会根据迭代器的类别优化其行为。
为什么需要 iterator_category
标准库中的算法(如 std::sort、std::find 等)需要知道迭代器支持哪些操作,以便选择最优的实现方式。例如:
- 对于随机访问迭代器,可以使用快速的随机访问算法(如快速排序)。
- 对于双向迭代器,只能使用适用于双向迭代的算法(如归并排序)。
- 对于输入迭代器,只能进行单次遍历,许多复杂算法无法使用。
通过指定 iterator_category,你可以让标准算法了解你自定义迭代器的能力,从而选择合适的方法进行操作。
iterator_category 的声明
在你的自定义迭代器类中,通过以下方式声明迭代器类别:
using iterator_category = std::bidirectional_iterator_tag;
这表示该迭代器是一个 双向迭代器,支持向前和向后遍历。
4. std::bidirectional_iterator_tag 详解
std::bidirectional_iterator_tag 是一个标签(Tag),用于标识迭代器类别。C++ 标准库中有多个这样的标签,分别对应不同的迭代器类别:
std::input_iterator_tagstd::output_iterator_tagstd::forward_iterator_tagstd::bidirectional_iterator_tagstd::random_access_iterator_tagstd::contiguous_iterator_tag(C++20)
这些标签本质上是空的结构体,用于类型区分。在标准算法中,通常会通过这些标签进行 重载选择(Overload Resolution) 或 特化(Specialization),以实现针对不同迭代器类别的优化。
继承关系
迭代器标签是有继承关系的:
std::forward_iterator_tag继承自std::input_iterator_tagstd::bidirectional_iterator_tag继承自std::forward_iterator_tagstd::random_access_iterator_tag继承自std::bidirectional_iterator_tagstd::contiguous_iterator_tag继承自std::random_access_iterator_tag
这种继承关系反映了迭代器类别的能力层级。例如,双向迭代器 具备 前向迭代器 的所有能力,加上反向遍历的能力。
5. 迭代器特性(Iterator Traits)详解
C++ 提供了 迭代器特性(Iterator Traits),通过模板类 std::iterator_traits 来获取迭代器的相关信息。通过这些特性,标准算法可以泛化地处理不同类型的迭代器。
迭代器特性包含的信息
std::iterator_traits 提供以下信息:
iterator_category:迭代器类别标签。value_type:迭代器指向的元素类型。difference_type:迭代器间的距离类型(通常是std::ptrdiff_t)。pointer:指向元素的指针类型。reference:对元素的引用类型。
自定义迭代器与 iterator_traits
当你定义自己的迭代器时,确保提供这些类型别名,以便标准库算法能够正确识别和使用你的迭代器。例如:
template<typename T>
class Iterator {
public:
using iterator_category = std::bidirectional_iterator_tag;
using value_type = T;
using difference_type = std::ptrdiff_t;
using pointer = T*;
using reference = T&;
// 其他成员函数...
};
这样,使用 std::iterator_traits<Iterator<T>> 时,就能正确获取迭代器的特性。
deque:双端队列
用法
deque(双端队列)是一种支持在两端高效插入和删除元素的序列容器。与vector相比,deque支持在前端和后端均以常数时间进行插入和删除操作。
内部实现原理
deque通常由一系列固定大小的数组块组成,这些块通过一个中央映射数组进行管理。这种结构使得在两端扩展时不需要重新分配整个容器的内存,从而避免了vector在前端插入的高成本。
性能特性
- 随机访问:支持常数时间的随机访问(
O(1))。 - 前后插入/删除:在前端和后端插入和删除元素的操作都是常数时间(
O(1))。 - 中间插入/删除:在中间位置插入或删除元素需要移动元素,时间复杂度为线性时间(
O(n))。
应用场景
- 需要在容器两端频繁插入和删除元素。
- 需要随机访问元素。
- 不需要频繁在中间位置插入和删除元素。
双端队列简介
双端队列(deque)是一种序列容器,允许在其两端高效地插入和删除元素。与vector不同,deque不仅支持在末尾添加或删除元素(如vector),还支持在头部进行同样的操作。此外,deque提供了随机访问能力,可以像vector一样通过索引访问元素。
主要特点
- 双端操作:支持在头部和尾部高效的插入和删除操作。
- 随机访问:可以像数组和
vector一样通过索引访问元素。 - 动态大小:可以根据需要增长和收缩,无需预先定义大小。
内存分配策略
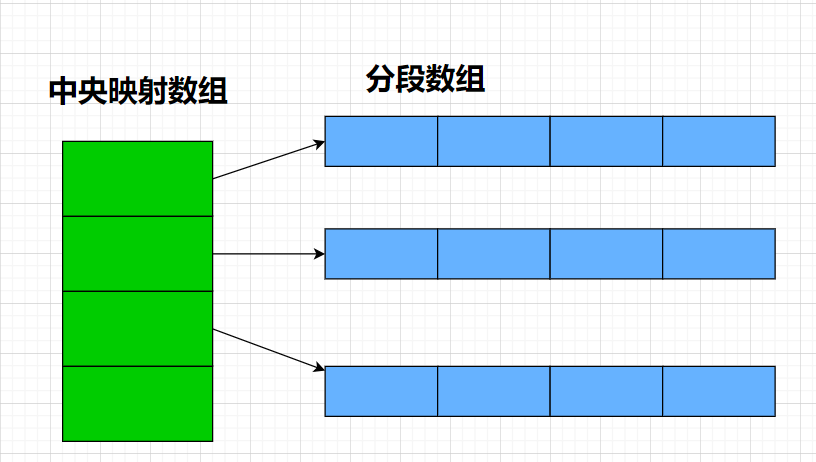
deque内部并不使用一个单一的连续内存块,而是将元素分割成多个固定大小的块(也称为缓冲区或页面),并通过一个中央映射数组(通常称为map)来管理这些块。具体来说,deque的内部结构可以分为以下几个部分:
- 中央映射数组(Map):
- 一个指针数组,指向各个数据块。
map本身也是动态分配的,可以根据需要增长或收缩。map允许deque在两端添加新的数据块,而无需移动现有的数据块。
- 数据块(Blocks):
- 每个数据块是一个固定大小的连续内存区域,用于存储元素。
- 数据块的大小通常与编译器和平台相关,但在大多数实现中,数据块的大小在运行时是固定的(如512字节或更多,具体取决于元素类型的大小)。
- 起始和结束指针:
deque维护指向中央映射数组中第一个有效数据块的指针以及第一个无效数据块的指针。- 这些指针帮助
deque快速地在两端添加或删除数据块。
双端队列的操作实现
插入操作
在末尾插入 (push_back)
- 检查当前末端数据块的剩余空间:
- 如果有空间,直接在当前末端数据块中插入新元素。
- 如果没有空间,分配一个新的数据块,并将其指针添加到
map中,然后在新块中插入元素。
- 更新末尾指针:
- 如果分配了新块,末尾指针指向该块的第一个元素。
- 否则,末尾指针移动到当前末端数据块的下一个位置。
在前端插入 (push_front)
- 检查当前前端数据块的剩余空间:
- 如果有空间,直接在当前前端数据块中插入新元素。
- 如果没有空间,分配一个新的数据块,并将其指针添加到
map的前面,然后在新块中插入元素。
- 更新前端指针:
- 如果分配了新块,前端指针指向该块的最后一个元素。
- 否则,前端指针移动到当前前端数据块的前一个位置。
删除操作
从末尾删除 (pop_back)
检查末端数据块是否有元素
:
- 如果有,移除最后一个元素,并更新末尾指针。
- 如果数据块变为空,释放该数据块并从
map中移除其指针,然后更新末尾指针指向前一个块。
从前端删除 (pop_front)
检查前端数据块是否有元素
:
- 如果有,移除第一个元素,并更新前端指针。
- 如果数据块变为空,释放该数据块并从
map中移除其指针,然后更新前端指针指向下一个块。
访问操作
随机访问
deque支持通过索引进行随机访问,其内部机制如下:
- 计算元素的位置:
- 根据给定的索引,确定对应的数据块和数据块内的偏移量。
- 使用
map数组定位到具体的块,然后通过偏移量定位到块内的元素。
- 访问元素:
- 一旦定位到具体的位置,即可像数组一样访问元素。
迭代器访问
deque提供双向迭代器,支持使用标准的C++迭代器操作(如++、--等)进行遍历。
双端队列的性能特性
理解deque的内部实现有助于理解其性能特性。以下是deque的主要操作及其时间复杂度:
| 操作 | 时间复杂度 | 说明 |
|---|---|---|
| 随机访问(通过索引) | 常数时间(O(1)) | 通过计算块和偏移量直接访问元素 |
| 插入/删除前端 | 常数时间(O(1)) | 仅涉及前端指针和可能的数据块分配 |
| 插入/删除末端 | 常数时间(O(1)) | 仅涉及末端指针和可能的数据块分配 |
| 中间插入/删除 | 线性时间(O(n)) | 需要移动数据块内的元素,可能涉及多个块的操作 |
| 查找元素 | 线性时间(O(n)) | 需要遍历元素进行查找 |
| 插入单个元素 | 平均常数时间(O(1)) | 在前端或末端插入,通常不需移动大量元素 |
| 插入大量元素 | 线性时间(O(n)) | 需要分配新的数据块并进行元素复制 |
优缺点
优点
- 双端操作高效:在两端插入和删除元素非常快速,不需要移动大量元素。
- 支持随机访问:可以像
vector一样通过索引高效访问元素。 - 动态增长:无需预先定义大小,可以根据需要自动调整。
缺点
- 内存碎片:由于使用多个数据块,可能导致内存碎片,尤其是在大量插入和删除操作后。
- 较低的局部性:元素不连续存储,可能导致缓存未命中率较高,影响性能。
- 复杂性较高:内部实现相对复杂,不如
vector直接高效。
双端队列与其他容器的比较
| 特性 | vector |
deque |
list |
|---|---|---|---|
| 内存结构 | 单一连续内存块 | 多块连续内存,通过映射数组管理 | 双向链表 |
| 随机访问 | 是,常数时间(O(1)) | 是,常数时间(O(1)) | 否,需要线性时间(O(n)) |
| 前端插入/删除 | 低效,线性时间(O(n)) | 高效,常数时间(O(1)) | 高效,常数时间(O(1)) |
| 末端插入/删除 | 高效,常数时间(O(1)) | 高效,常数时间(O(1)) | 高效,常数时间(O(1)) |
| 内存碎片 | 低,由于单一连续内存块 | 较高,由于多块内存管理 | 较高,由于节点分散在内存中 |
| 元素隔离 | 高,局部性较好 | 中等,分块存储提高了部分局部性 | 低,元素分散存储,缓存效率低 |
| 应用场景 | 需要频繁随机访问、末端操作的场景 | 需要频繁在两端插入/删除且偶尔随机访问的场景 | 需要频繁在中间插入/删除且不需要随机访问的场景 |
代码示例
#include <iostream>
#include <deque>
int main() {
// 创建一个空的deque
std::deque<std::string> dq;
// 在末尾添加元素
dq.push_back("End1");
dq.push_back("End2");
// 在前端添加元素
dq.push_front("Front1");
dq.push_front("Front2");
// 遍历deque
std::cout << "deque中的元素: ";
for(auto it = dq.begin(); it != dq.end(); ++it) {
std::cout << *it << " ";
}
std::cout << std::endl;
// 访问首尾元素
std::cout << "首元素: " << dq.front() << std::endl;
std::cout << "尾元素: " << dq.back() << std::endl;
// 删除首元素
dq.pop_front();
// 删除尾元素
dq.pop_back();
// 打印删除后的deque
std::cout << "删除首尾元素后: ";
for(auto num : dq) {
std::cout << num << " ";
}
std::cout << std::endl;
return 0;
}
输出
deque中的元素: Front2 Front1 End1 End2
首元素: Front2
尾元素: End2
删除首尾元素后: Front1 End1
map和unordered_map:关联数组
map用法与原理
用法
map是一个关联容器,用于存储键值对(key-value)。它基于键自动排序,且每个键都是唯一的。map提供了快速的查找、插入和删除操作。
内部实现原理
map通常使用自平衡的二叉搜索树(如红黑树)实现。这确保了所有操作的时间复杂度为对数时间(O(log n)),且元素按照键的顺序排列。
unordered_map用法与原理
用法
unordered_map也是一种关联容器,用于存储键值对,但它不保证元素的顺序。unordered_map基于哈希表实现,提供了平均常数时间(O(1))的查找、插入和删除操作。
内部实现原理
unordered_map使用哈希表来存储元素。键通过哈希函数转换为哈希值,并映射到特定的桶中。如果多个键映射到同一桶,会通过链表或其他方法解决冲突。
性能对比
| 操作 | map |
unordered_map |
|---|---|---|
| 查找 | O(log n) |
平均 O(1) |
| 插入 | O(log n) |
平均 O(1) |
| 删除 | O(log n) |
平均 O(1) |
| 内存使用 | 较高 | 较低 |
| 元素顺序 | 有序 | 无序 |
应用场景
map:- 需要按键的顺序遍历元素。
- 需要有序的关联数组。
- 需要高效的范围查找。
unordered_map:- 对元素顺序没有要求。
- 需要极高效的查找、插入和删除操作。
- 不需要自定义的排序规则。
代码示例
map示例
#include <iostream>
#include <map>
#include <string>
int main() {
// 创建一个空的map,键为string,值为int
std::map<std::string, int> ageMap;
// 插入键值对
ageMap["Alice"] = 30;
ageMap["Bob"] = 25;
ageMap["Charlie"] = 35;
// 查找元素
std::string name = "Bob";
if(ageMap.find(name) != ageMap.end()) {
std::cout << name << " 的年龄是 " << ageMap[name] << std::endl;
} else {
std::cout << "未找到 " << name << std::endl;
}
// 遍历map
std::cout << "所有人员和年龄: " << std::endl;
for(auto it = ageMap.begin(); it != ageMap.end(); ++it) {
std::cout << it->first << " : " << it->second << std::endl;
}
// 删除元素
ageMap.erase("Alice");
// 打印删除后的map
std::cout << "删除Alice后: " << std::endl;
for(auto &[key, value] : ageMap) {
std::cout << key << " : " << value << std::endl;
}
return 0;
}
unordered_map示例
#include <iostream>
#include <unordered_map>
#include <string>
int main() {
// 创建一个空的unordered_map,键为string,值为double
std::unordered_map<std::string, double> priceMap;
// 插入键值对
priceMap["Apple"] = 1.2;
priceMap["Banana"] = 0.5;
priceMap["Orange"] = 0.8;
// 查找元素
std::string fruit = "Banana";
if(priceMap.find(fruit) != priceMap.end()) {
std::cout << fruit << " 的价格是 $" << priceMap[fruit] << std::endl;
} else {
std::cout << "未找到 " << fruit << std::endl;
}
// 遍历unordered_map
std::cout << "所有水果和价格: " << std::endl;
for(auto &[key, value] : priceMap) {
std::cout << key << " : $" << value << std::endl;
}
// 删除元素
priceMap.erase("Apple");
// 打印删除后的unordered_map
std::cout << "删除Apple后: " << std::endl;
for(auto &[key, value] : priceMap) {
std::cout << key << " : $" << value << std::endl;
}
return 0;
}
输出
map输出
Bob 的年龄是 25
所有人员和年龄:
Alice : 30
Bob : 25
Charlie : 35
删除Alice后:
Bob : 25
Charlie : 35
unordered_map输出
Banana 的价格是 $0.5
所有水果和价格:
Apple : $1.2
Banana : $0.5
Orange : $0.8
删除Apple后:
Banana : $0.5
Orange : $0.8
set和unordered_set:集合
set用法与原理
用法
set是一个关联容器,用于存储唯一的、有序的元素。set基于键自动排序,且每个元素都是唯一的。
内部实现原理
set通常使用自平衡的二叉搜索树(如红黑树)实现,保证元素按顺序排列。每次插入元素时,都会自动保持树的平衡,并确保元素的唯一性。
unordered_set用法与原理
用法
unordered_set也是一种集合容器,用于存储唯一的元素,但它不保证元素的顺序。unordered_set基于哈希表实现,提供了平均常数时间(O(1))的查找、插入和删除操作。
内部实现原理
unordered_set使用哈希表存储元素。每个元素通过哈希函数转换为哈希值,并映射到特定的桶中。冲突通过链表或其他方法解决。
性能对比
| 操作 | set |
unordered_set |
|---|---|---|
| 查找 | O(log n) |
平均 O(1) |
| 插入 | O(log n) |
平均 O(1) |
| 删除 | O(log n) |
平均 O(1) |
| 内存使用 | 较高 | 较低 |
| 元素顺序 | 有序 | 无序 |
应用场景
set:- 需要有序的唯一元素集合。
- 需要按顺序遍历元素。
- 需要基于区间的操作(如查找、删除某范围的元素)。
unordered_set:- 对元素顺序无要求。
- 需要极高效的查找、插入和删除操作。
- 不需要自定义的排序规则。
代码示例
set示例
#include <iostream>
#include <set>
int main() {
// 创建一个空的整数set
std::set<int> numbers;
// 插入元素
numbers.insert(10);
numbers.insert(20);
numbers.insert(30);
numbers.insert(20); // 重复元素,不会被插入
// 遍历set
std::cout << "set中的元素: ";
for(auto it = numbers.begin(); it != numbers.end(); ++it) {
std::cout << *it << " ";
}
std::cout << std::endl;
// 查找元素
int key = 20;
if(numbers.find(key) != numbers.end()) {
std::cout << key << " 在set中存在。" << std::endl;
} else {
std::cout << key << " 不在set中。" << std::endl;
}
// 删除元素
numbers.erase(10);
// 打印删除后的set
std::cout << "删除10后set中的元素: ";
for(auto num : numbers) {
std::cout << num << " ";
}
std::cout << std::endl;
return 0;
}
unordered_set示例
#include <iostream>
#include <unordered_set>
int main() {
// 创建一个空的unordered_set
std::unordered_set<int> numbers;
// 插入元素
numbers.insert(10);
numbers.insert(20);
numbers.insert(30);
numbers.insert(20); // 重复元素,不会被插入
// 遍历unordered_set
std::cout << "unordered_set中的元素: ";
for(auto it = numbers.begin(); it != numbers.end(); ++it) {
std::cout << *it << " ";
}
std::cout << std::endl;
// 查找元素
int key = 20;
if(numbers.find(key) != numbers.end()) {
std::cout << key << " 在unordered_set中存在。" << std::endl;
} else {
std::cout << key << " 不在unordered_set中。" << std::endl;
}
// 删除元素
numbers.erase(10);
// 打印删除后的unordered_set
std::cout << "删除10后unordered_set中的元素: ";
for(auto num : numbers) {
std::cout << num << " ";
}
std::cout << std::endl;
return 0;
}
输出
set输出
set中的元素: 10 20 30
20 在set中存在。
删除10后set中的元素: 20 30
unordered_set输出(注意元素顺序可能不同)
unordered_set中的元素: 10 20 30
20 在unordered_set中存在。
删除10后unordered_set中的元素: 20 30
stack、queue和priority_queue:容器适配器
用法
STL中的容器适配器(stack、queue、priority_queue)提供了特定的数据结构接口,这些适配器在内部使用其他容器来存储元素(默认使用deque或vector)。
内部实现原理
stack:后进先出(LIFO)数据结构,通常使用deque或vector作为底层容器,通过限制操作接口来实现。queue:先进先出(FIFO)数据结构,通常使用deque作为底层容器,通过限制操作接口来实现。priority_queue:基于堆的数据结构,通常使用vector作为底层容器,并通过堆算法(如std::make_heap、std::push_heap、std::pop_heap)维护元素的优先级顺序。
性能特性
stack:- 访问顶部元素:
O(1) - 插入和删除:
O(1)
- 访问顶部元素:
queue:- 访问前端和后端元素:
O(1) - 插入和删除:
O(1)
- 访问前端和后端元素:
priority_queue:- 访问顶部(最大或最小元素):
O(1) - 插入和删除:
O(log n)
- 访问顶部(最大或最小元素):
应用场景
stack:- 实现函数调用栈。
- 处理撤销操作。
- 深度优先搜索(DFS)。
queue:- 实现任务调度。
- 广度优先搜索(BFS)。
- 数据流处理。
priority_queue:- 实现优先级调度。
- 求解最短路径算法(如Dijkstra)。
- 任意需要按优先级处理元素的场景。
代码示例
stack示例
#include <iostream>
#include <stack>
int main() {
// 创建一个空的stack,底层使用vector
std::stack<int> s;
// 压入元素
s.push(1);
s.push(2);
s.push(3);
// 访问栈顶元素
std::cout << "栈顶元素: " << s.top() << std::endl;
// 弹出元素
s.pop();
std::cout << "弹出一个元素后,新的栈顶: " << s.top() << std::endl;
// 判断栈是否为空
if(!s.empty()) {
std::cout << "栈不为空,元素数量: " << s.size() << std::endl;
}
return 0;
}
queue示例
#include <iostream>
#include <queue>
int main() {
// 创建一个空的queue,底层使用deque
std::queue<std::string> q;
// 入队元素
q.push("First");
q.push("Second");
q.push("Third");
// 访问队首元素
std::cout << "队首元素: " << q.front() << std::endl;
// 访问队尾元素
std::cout << "队尾元素: " << q.back() << std::endl;
// 出队元素
q.pop();
std::cout << "出队后新的队首: " << q.front() << std::endl;
// 判断队列是否为空
if(!q.empty()) {
std::cout << "队列不为空,元素数量: " << q.size() << std::endl;
}
return 0;
}
priority_queue示例
#include <iostream>
#include <queue>
#include <vector>
int main() {
// 创建一个空的priority_queue,默认是最大堆
std::priority_queue<int> pq;
// 插入元素
pq.push(30);
pq.push(10);
pq.push(20);
pq.push(40);
// 访问堆顶元素
std::cout << "优先级最高的元素: " << pq.top() << std::endl;
// 弹出元素
pq.pop();
std::cout << "弹出一个元素后,新的堆顶: " << pq.top() << std::endl;
// 遍历priority_queue(需要复制,因为无法直接遍历)
std::priority_queue<int> copy = pq;
std::cout << "剩余的元素: ";
while(!copy.empty()) {
std::cout << copy.top() << " ";
copy.pop();
}
std::cout << std::endl;
return 0;
}
输出
stack输出
栈顶元素: 3
弹出一个元素后,新的栈顶: 2
栈不为空,元素数量: 2
queue输出
队首元素: First
队尾元素: Third
出队后新的队首: Second
队列不为空,元素数量: 2
priority_queue输出
优先级最高的元素: 40
弹出一个元素后,新的堆顶: 30
剩余的元素: 30 20 10
总结
C++ STL提供了丰富多样的容器,适用于各种不同的数据存储和管理需求。理解每种容器的特点、内部实现原理以及性能特性,可以帮助开发者在实际应用中做出最佳的选择,从而编写出高效且可维护的代码。
- 序列容器:
vector:适用于需要频繁随机访问和在末尾操作的场景。list:适用于需要在中间频繁插入和删除的场景。deque:适用于需要在两端频繁插入和删除的场景。
- 关联容器:
map\和*set*:适用于需要有序存储和快速查找的场景。unordered_map\和*unordered_set*:适用于需要高效查找且对元素顺序无要求的场景。
- 容器适配器:
stack:用于LIFO操作。queue:用于FIFO操作。priority_queue:用于优先级队列操作。